ไฟล์ Robots.txt ในโดเมนคืออะไร

หนึ่งในข้อผิดพลาดที่ยิ่งใหญ่ที่สุดสำหรับเจ้าของเว็บไซต์ใหม่คือการไม่ดูไฟล์ robots.txt แล้วมันคืออะไรและทำไมจึงสำคัญ? เรามีคำตอบของคุณ
หากคุณเป็นเจ้าของเว็บไซต์และใส่ใจเกี่ยวกับเว็บไซต์ของคุณสุขภาพ SEO คุณควรทำให้ตัวเองคุ้นเคยกับไฟล์ robots.txt ในโดเมนของคุณมากขึ้น เชื่อหรือไม่ว่าเป็นคนจำนวนมากที่กวนโดเมนอย่างรวดเร็วติดตั้งเว็บไซต์ WordPress อย่างรวดเร็วและไม่ต้องทำอะไรกับไฟล์ robots.txt
สิ่งนี้เป็นอันตราย ไฟล์ robots.txt ที่กำหนดค่าไม่ดีสามารถทำลายสุขภาพ SEO ของเว็บไซต์ของคุณและสร้างความเสียหายโอกาสที่คุณอาจมีต่อการเพิ่มอัตราการเข้าชม
ไฟล์ Robots.txt คืออะไร
คน Robots.txt ไฟล์ชื่อ aptly เพราะเป็นหลักไฟล์ที่แสดงคำสั่งสำหรับเว็บโรบ็อต (เช่นโรบ็อตของเครื่องมือค้นหา) เกี่ยวกับวิธีและสิ่งที่พวกเขาสามารถรวบรวมข้อมูลในเว็บไซต์ของคุณ นี่เป็นมาตรฐานเว็บที่ตามมาด้วยเว็บไซต์ตั้งแต่ปี 1994 และโปรแกรมรวบรวมข้อมูลเว็บที่สำคัญทั้งหมดเป็นไปตามมาตรฐาน
ไฟล์ถูกจัดเก็บในรูปแบบข้อความ (พร้อมกับนามสกุล txt) ในโฟลเดอร์รูทของเว็บไซต์ของคุณ อันที่จริงแล้วคุณสามารถดูไฟล์ robots.txt ของเว็บไซต์ใด ๆ เพียงแค่พิมพ์โดเมนตามด้วย /robots.txt หากคุณลองใช้ groovyPost คุณจะเห็นตัวอย่างของไฟล์ robot.txt ที่มีโครงสร้างที่ดี

ไฟล์นี้เรียบง่าย แต่มีประสิทธิภาพ ไฟล์ตัวอย่างนี้ไม่แยกความแตกต่างระหว่างโรบอต คำสั่งจะออกให้กับโรบอตทั้งหมดโดยใช้ ตัวแทนผู้ใช้: * คำสั่ง ซึ่งหมายความว่าคำสั่งทั้งหมดที่ตามมานำไปใช้กับหุ่นยนต์ทั้งหมดที่เข้าชมเว็บไซต์เพื่อรวบรวมข้อมูล
การระบุโปรแกรมรวบรวมข้อมูลเว็บ
คุณสามารถระบุกฎเฉพาะสำหรับซอฟต์แวร์รวบรวมข้อมูลเว็บเฉพาะ ตัวอย่างเช่นคุณอาจอนุญาตให้ Googlebot (โปรแกรมรวบรวมข้อมูลเว็บของ Google) รวบรวมข้อมูลบทความทั้งหมดในเว็บไซต์ของคุณ แต่คุณอาจไม่อนุญาตให้ใช้โปรแกรมรวบรวมข้อมูลเว็บ Yandex Bot ของรัสเซียจากการรวบรวมข้อมูลบทความในเว็บไซต์ของคุณที่มีข้อมูลที่ดูหมิ่นรัสเซีย
มีโปรแกรมรวบรวมข้อมูลเว็บหลายร้อยรายการที่กัดเซาะอินเทอร์เน็ตสำหรับข้อมูลเกี่ยวกับเว็บไซต์ แต่ 10 อันดับแรกที่คุณควรคำนึงถึงอยู่ในรายการที่นี่
- Googlebot: เครื่องมือค้นหาของ Google
- Bingbot: เครื่องมือค้นหา Bing ของ Microsoft
- Slurp: เครื่องมือค้นหาของ Yahoo
- DuckDuckBot: เครื่องมือค้นหา DuckDuckGo
- Baiduspider: เครื่องมือค้นหา Baidu ของจีน
- YandexBot: เครื่องมือค้นหา Yandex รัสเซีย
- Exabot: เครื่องมือค้นหา Exalead ของฝรั่งเศส
- Facebot: บอทรวบรวมข้อมูลของ Facebook
- ia_archiver: โปรแกรมรวบรวมการจัดอันดับเว็บของ Alexa
- MJ12bot: ฐานข้อมูลการทำดัชนีลิงค์ขนาดใหญ่
ยกตัวอย่างสถานการณ์ด้านบนถ้าคุณต้องการเพื่ออนุญาตให้ Googlebot จัดทำดัชนีทุกอย่างในเว็บไซต์ของคุณ แต่ต้องการบล็อก Yandex ไม่ให้จัดทำดัชนีเนื้อหาบทความจากรัสเซียคุณจะต้องเพิ่มบรรทัดต่อไปนี้ในไฟล์ robots.txt ของคุณ
User-agent: googlebot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
User-agent: yandexbot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
Disallow: /russia/
อย่างที่คุณเห็นส่วนแรกจะบล็อกเท่านั้นGoogle จากการรวบรวมข้อมูลหน้าเข้าสู่ระบบ WordPress และหน้าการดูแลระบบของคุณ ส่วนที่สองบล็อก Yandex จากที่เหมือนกัน แต่มาจากพื้นที่ทั้งหมดของไซต์ที่คุณตีพิมพ์บทความที่มีเนื้อหาต่อต้านรัสเซีย
นี่เป็นตัวอย่างง่ายๆของวิธีที่คุณสามารถใช้ ไม่อนุญาต คำสั่งเพื่อควบคุมโปรแกรมรวบรวมข้อมูลเว็บเฉพาะที่เยี่ยมชมเว็บไซต์ของคุณ
คำสั่ง Robots.txt อื่น ๆ
ไม่อนุญาตคำสั่งเดียวที่คุณมีสิทธิ์เข้าถึงในไฟล์ robots.txt ของคุณ นอกจากนี้คุณยังสามารถใช้คำสั่งอื่น ๆ ที่จะกำหนดวิธีที่โรบ็อตสามารถรวบรวมข้อมูลเว็บไซต์ของคุณ
- ไม่อนุญาต: บอกตัวแทนผู้ใช้เพื่อหลีกเลี่ยงการรวบรวมข้อมูล URL ที่เฉพาะเจาะจงหรือส่วนทั้งหมดของเว็บไซต์ของคุณ
- อนุญาต: ช่วยให้คุณปรับหน้าเว็บหรือโฟลเดอร์ย่อยเฉพาะบนไซต์ของคุณแม้ว่าคุณอาจไม่อนุญาตให้ใช้โฟลเดอร์หลัก ตัวอย่างเช่นคุณสามารถไม่อนุญาต: / about / แต่อนุญาต: / about / ryan /
- การรวบรวมข้อมูลล่าช้า: สิ่งนี้บอกให้โปรแกรมรวบรวมข้อมูลรอประมาณ xx วินาทีก่อนที่จะเริ่มรวบรวมข้อมูลเนื้อหาของเว็บไซต์
- Sitemap: ระบุเครื่องมือค้นหา (Google, Ask, Bing และ Yahoo) ที่ตั้งของแผนผังไซต์ XML ของคุณ
โปรดจำไว้ว่าบอตจะ เพีย ฟังคำสั่งที่คุณให้ไว้เมื่อคุณระบุชื่อของบอท
ข้อผิดพลาดทั่วไปที่ผู้คนทำคือไม่อนุญาตพื้นที่เช่น / wp-admin / จากบอตทั้งหมด แต่จากนั้นระบุส่วน googlebot และไม่อนุญาตเฉพาะพื้นที่อื่น ๆ (เช่น / about /)
เนื่องจากบอตเพียงทำตามคำสั่งที่คุณระบุในส่วนของพวกเขาคุณจะต้องปรับปรุงคำสั่งอื่น ๆ ทั้งหมดที่คุณระบุสำหรับบอตทั้งหมด (โดยใช้ * user-agent)
- ไม่อนุญาต: คำสั่งที่ใช้บอกตัวแทนผู้ใช้ไม่ให้ตระเวน URL ที่เจาะจง อนุญาตให้แต่ละบรรทัด“ ไม่อนุญาต:” หนึ่งบรรทัดเท่านั้น
- อนุญาต (ใช้ได้กับ Googlebot เท่านั้น): คำสั่งเพื่อแจ้งให้ Googlebot ทราบว่าสามารถเข้าถึงหน้าหรือโฟลเดอร์ย่อยแม้ว่าหน้าหลักหรือโฟลเดอร์ย่อยอาจไม่ได้รับอนุญาต
- การรวบรวมข้อมูลล่าช้า: โปรแกรมรวบรวมข้อมูลควรรอสักครู่ก่อนโหลดและรวบรวมข้อมูลเนื้อหาของหน้าเว็บ โปรดทราบว่า Googlebot ไม่ยอมรับคำสั่งนี้ แต่สามารถตั้งอัตราการรวบรวมข้อมูลไว้ใน Google Search Console
- แผนผังเว็บไซต์: ใช้เพื่อโทรออกตำแหน่งของแผนผังไซต์ XML ที่เชื่อมโยงกับ URL นี้ หมายเหตุคำสั่งนี้รองรับโดย Google, Ask, Bing และ Yahoo เท่านั้น
โปรดทราบว่า robots.txt มีวัตถุประสงค์เพื่อช่วยบอทที่ถูกกฎหมาย (เช่นบ็อตเครื่องมือค้นหา) รวบรวมข้อมูลเว็บไซต์ของคุณได้อย่างมีประสิทธิภาพยิ่งขึ้น
มีโปรแกรมรวบรวมข้อมูลที่เลวร้ายมากมายอยู่ที่นั่นที่กำลังรวบรวมข้อมูลเว็บไซต์ของคุณเพื่อทำสิ่งต่างๆเช่นที่อยู่อีเมลที่ถูกขูดหรือขโมยเนื้อหาของคุณ หากคุณต้องการลองใช้ไฟล์ robots.txt ของคุณเพื่อป้องกันโปรแกรมรวบรวมข้อมูลเหล่านั้นไม่ให้รวบรวมข้อมูลใด ๆ ในเว็บไซต์ของคุณอย่ากังวล ผู้สร้างซอฟต์แวร์รวบรวมข้อมูลเหล่านั้นจะไม่สนใจสิ่งที่คุณใส่ไว้ในไฟล์ robots.txt ของคุณ
ทำไมไม่อนุญาตอะไรเลย
ทำให้เครื่องมือค้นหาของ Google รวบรวมข้อมูลเนื้อหาที่มีคุณภาพในเว็บไซต์ของคุณให้ได้มากที่สุดเป็นข้อกังวลหลักสำหรับเจ้าของเว็บไซต์ส่วนใหญ่
อย่างไรก็ตาม Google จะมีข้อ จำกัด งบประมาณการรวบรวมข้อมูล แล้ว อัตราการรวบรวมข้อมูล ในแต่ละเว็บไซต์ อัตราการรวบรวมข้อมูลคือจำนวนคำขอต่อวินาทีที่ Googlebot จะส่งมายังไซต์ของคุณในระหว่างการรวบรวมข้อมูล
ที่สำคัญกว่าคืองบประมาณการรวบรวมข้อมูลซึ่งเป็นอย่างไรคำขอทั้งหมดจำนวนมากที่ Googlebot จะรวบรวมข้อมูลเว็บไซต์ของคุณในเซสชันเดียว Google“ ใช้จ่าย” งบประมาณการรวบรวมข้อมูลโดยมุ่งเน้นที่ส่วนต่างๆของไซต์ของคุณที่ได้รับความนิยมมากหรือมีการเปลี่ยนแปลงเมื่อเร็ว ๆ นี้
คุณไม่ได้ตาบอดกับข้อมูลนี้ หากคุณไปที่ Google เครื่องมือของผู้ดูแลเว็บคุณสามารถดูว่าซอฟต์แวร์รวบรวมข้อมูลนั้นจัดการไซต์ของคุณอย่างไร

อย่างที่คุณเห็นโปรแกรมรวบรวมข้อมูลจะเก็บกิจกรรมไว้ในเว็บไซต์ของคุณค่อนข้างคงที่ทุกวัน มันไม่ได้รวบรวมข้อมูลทุกไซต์ แต่เฉพาะเว็บไซต์ที่คิดว่าสำคัญที่สุดเท่านั้น
เหตุใดจึงต้องขึ้นอยู่กับ Googlebot เพื่อตัดสินใจว่ามีอะไรสำคัญในไซต์ของคุณเมื่อคุณสามารถใช้ไฟล์ robots.txt เพื่อบอกว่าหน้าใดที่สำคัญที่สุดคืออะไร วิธีนี้จะป้องกันไม่ให้ Googlebot เสียเวลาในหน้าเว็บที่มีมูลค่าต่ำในเว็บไซต์ของคุณ
เพิ่มประสิทธิภาพงบประมาณการรวบรวมข้อมูลของคุณ
Google Webmaster Tools ช่วยให้คุณตรวจสอบว่า Googlebot กำลังอ่านไฟล์ robots.txt ของคุณหรือไม่และมีข้อผิดพลาดหรือไม่
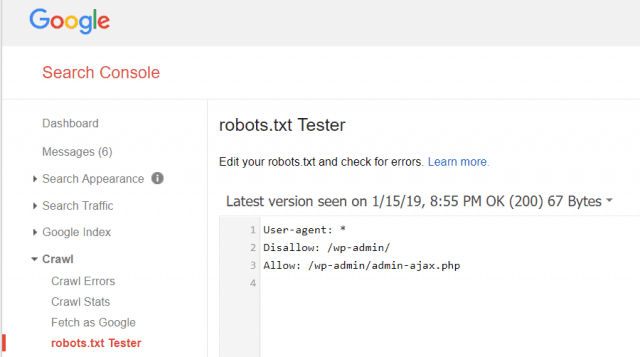
สิ่งนี้จะช่วยให้คุณตรวจสอบว่าคุณได้จัดโครงสร้างไฟล์ robots.txt ของคุณอย่างถูกต้อง
หน้าใดที่คุณไม่ควรอนุญาตจาก Googlebot เป็นการดีที่ไซต์ของคุณจะทำ SEO เพื่อไม่อนุญาตหมวดหมู่ของหน้าต่อไปนี้
- ทำซ้ำหน้ากระดาษ (เช่นหน้ากระดาษสำหรับเครื่องพิมพ์)
- ขอบคุณหน้าต่อไปนี้คำสั่งซื้อตามแบบฟอร์ม
- แบบฟอร์มการสั่งซื้อหรือสอบถามข้อมูล
- หน้าติดต่อ
- หน้าเข้าสู่ระบบ
- แม่เหล็กตะกั่ว“ ขาย” หน้า
อย่าเพิกเฉยไฟล์ Robots.txt ของคุณ
ความผิดพลาดครั้งใหญ่ที่สุดที่เจ้าของเว็บไซต์ใหม่ทำคือไม่เคยแม้แต่จะดูไฟล์ robots.txt ของพวกเขา สถานการณ์ที่เลวร้ายที่สุดอาจเป็นได้ว่าไฟล์ robots.txt กำลังปิดกั้นเว็บไซต์ของคุณหรือพื้นที่ของไซต์ของคุณจากการรวบรวมข้อมูลเลย
ตรวจสอบให้แน่ใจว่าได้ตรวจสอบไฟล์ robots.txt ของคุณและตรวจสอบให้แน่ใจว่าได้รับการปรับปรุง ด้วยวิธีนี้ Google และเครื่องมือค้นหาสำคัญอื่น ๆ “ ดู” ทุกสิ่งที่ยอดเยี่ยมที่คุณมอบให้กับเว็บไซต์ของคุณ
![เข้าร่วมโดเมน Windows ของ Active Directory กับ Windows 7 หรือ Vista [วิธีจัดการ]](/images/vista/join-an-active-directory-windows-domain-with-windows-7-or-vista-how-to.png)









ทิ้งข้อความไว้