ドメイン内のRobots.txtファイルとは何ですか?

新しいWebサイトの所有者にとっての最大の間違いの1つは、robots.txtファイルを確認しないことです。とにかくそれは何ですか、なぜそんなに重要なのですか?あなたの答えがあります。
ウェブサイトを所有していて、サイトのSEOの健全性については、ドメインのrobots.txtファイルに精通している必要があります。信じられないかもしれませんが、それはドメインをすぐに起動し、簡単なWordPress Webサイトをインストールし、robots.txtファイルで何もしません。
これは危険です。適切に設定されていないrobots.txtファイルは、実際にサイトのSEOの健全性を破壊し、トラフィックを増やす可能性を損なう可能性があります。
Robots.txtファイルとは何ですか?
の Robots.txt ファイルは本質的にウェブロボット(検索エンジンロボットなど)がウェブサイトでどのように、どのようにクロールできるかに関するディレクティブをリストしたファイル。これは1994年以来Webサイトが続いているWeb標準であり、すべての主要なWebクローラーは標準に準拠しています。
ファイルはテキスト形式で保存されます(。ウェブサイトのルートフォルダーにあるtxt拡張子)。実際、ドメインに続けて/robots.txtを入力するだけで、任意のウェブサイトのrobot.txtファイルを表示できます。 groovyPostでこれを試すと、適切に構成されたrobot.txtファイルの例が表示されます。

ファイルはシンプルですが効果的です。このサンプルファイルは、ロボットを区別しません。コマンドは、次を使用してすべてのロボットに発行されます ユーザーエージェント: * 指令。つまり、それに続くすべてのコマンドは、サイトをクロールするためにサイトにアクセスするすべてのロボットに適用されます。
Webクローラーの指定
特定のルールを指定することもできます特定のWebクローラー。たとえば、Googlebot(Googleのウェブクローラー)がサイト上のすべての記事をクロールできるようにする一方で、ロシアのウェブクローラーYandex Botがロシアに関する中傷的な情報を含むサイト上の記事をクロールできないようにすることができます。
ウェブサイトについての情報を求めてインターネットを探し回る何百ものウェブクローラーがありますが、あなたが心配するべきである最も一般的な10がここにリストされています。
- Googlebot:Google検索エンジン
- ビングボット:MicrosoftのBing検索エンジン
- 丸lurみ:Yahoo検索エンジン
- DuckDuckBot:DuckDuckGo検索エンジン
- バイデュスパイダー:中国のバイドゥ検索エンジン
- YandexBot:ロシアのYandex検索エンジン
- Exabot:フランスのExalead検索エンジン
- Facebot:Facebookのクロールボット
- ia_archiver:AlexaのWebランキングクローラー
- MJ12bot:大規模なリンクインデックスデータベース
必要に応じて、上記のシナリオ例を使用しますGooglebotがサイト上のすべてのインデックスを作成できるようにしながら、Yandexがロシア語ベースの記事コンテンツのインデックスを作成しないようにするには、robots.txtファイルに次の行を追加します。
User-agent: googlebot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
User-agent: yandexbot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
Disallow: /russia/
ご覧のとおり、最初のセクションはブロックするだけですGoogleはWordPressのログインページと管理ページをクロールしません。 2番目のセクションは、Yandexをブロックしますが、反ロシア語コンテンツを含む記事を公開したサイト全体からもブロックします。
これは、使用方法の簡単な例です 許可しない ウェブサイトにアクセスする特定のウェブクローラーを制御するコマンド。
その他のRobots.txtコマンド
robots.txtファイルでアクセスできるコマンドはDisallowだけではありません。ロボットがサイトをクロールする方法を指示する他のコマンドを使用することもできます。
- 許可しない:特定のURLまたはサイトのセクション全体をクロールしないようにユーザーエージェントに指示します。
- 許可する:親フォルダを許可していない場合でも、サイト上の特定のページまたはサブフォルダを微調整できます。たとえば、/ about /を許可せずに、/ about / ryan /を許可できます。
- クロール遅延:これにより、サイトのコンテンツのクロールを開始する前にxx秒待機するようにクローラーに指示します。
- サイトマップ: 検索サイト(Google、Ask、Bing、Yahoo)にXMLサイトマップの場所を提供します。
ボットは のみ ボットの名前を指定するときに指定したコマンドを聞いてください。
よくある間違いは、すべてのボットから/ wp-admin /などの領域を禁止しますが、googlebotセクションを指定し、他の領域(/ about /など)のみを禁止することです。
ボットはセクションで指定したコマンドのみに従うため、すべてのボットに指定した他のすべてのコマンドを(*ユーザーエージェントを使用して)再度記述する必要があります。
- 許可しない:ユーザーエージェントに特定のURLをクロールしないように指示するために使用されるコマンド。各URLに許可される「Disallow:」行は1行のみです。
- 許可(Googlebotにのみ適用):親ページまたはサブフォルダーが許可されていない場合でも、ページまたはサブフォルダーにアクセスできることをGooglebotに伝えるコマンド。
- クロール遅延:ページコンテンツを読み込んでクロールするまでにクローラーが待機する秒数。 Googlebotはこのコマンドを認識しませんが、クロールレートはGoogle Search Consoleで設定できることに注意してください。
- サイトマップ:このURLに関連付けられたXMLサイトマップの場所を呼び出すために使用されます。このコマンドは、Google、Ask、Bing、Yahooでのみサポートされています。
robots.txtは、正当なボット(検索エンジンボットなど)がサイトをより効果的にクロールするのに役立つことに留意してください。
そこには多くの邪悪なクローラーがいますサイトをクロールして、メールアドレスを盗んだり、コンテンツを盗んだりします。 robots.txtファイルを使用して、これらのクローラがサイト上の何かをクロールするのをブロックする場合は、気にしないでください。これらのクローラーの作成者は、通常、robots.txtファイルに入力した内容を無視します。
何も許可しないのはなぜですか?
ほとんどのウェブサイト所有者にとって、Googleの検索エンジンがウェブサイト上の可能な限り高品質のコンテンツをクロールできるようにすることが最大の関心事です。
ただし、Googleは限られた クロール予算 そして クロール速度 個々のサイトで。クロールレートは、クロールイベント中にGooglebotがサイトに送信する1秒あたりのリクエスト数です。
より重要なのはクロール予算です。1回のセッションでGooglebotがサイトをクロールするために行う合計リクエストの多く。 Googleは、非常に人気のあるまたは最近変更されたサイトの領域に焦点を当てることにより、クロール予算を「使い果たします」。
あなたはこの情報に盲目ではありません。 Googleウェブマスターツールにアクセスすると、クローラーがサイトをどのように処理しているかを確認できます。

ご覧のとおり、クローラーはサイト上のアクティビティを毎日ほぼ一定に保ちます。すべてのサイトをクロールするわけではありませんが、最も重要と見なされるサイトのみをクロールします。
何がGooglebotに任せて何を決めるのかrobots.txtファイルを使用して最も重要なページを伝えることができる場合、サイトで重要ですか?これにより、Googlebotがサイトの価値の低いページで時間を無駄にすることを防ぎます。
クロール予算を最適化する
Googleウェブマスターツールでは、Googlebotがrobots.txtファイルを正常に読み取っているかどうか、エラーがないかどうかも確認できます。
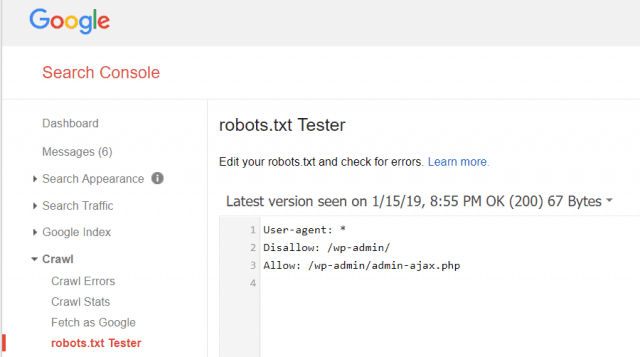
これにより、robots.txtファイルが正しく構成されていることを確認できます。
Googlebotから許可しないページは何ですか?サイトのSEOにとって、次のカテゴリのページを禁止するのは良いことです。
- 重複ページ(印刷しやすいページなど)
- フォームベースの注文に続くありがとうページ
- 注文または情報照会フォーム
- お問い合わせページ
- ログインページ
- リードマグネット「販売」ページ
Robots.txtファイルを無視しないでください
新しいウェブサイトの所有者が犯す最大の間違いはrobots.txtファイルを見ることもありません。最悪の状況は、robots.txtファイルが実際にサイトまたはサイトの一部をクロールしないようブロックしていることです。
robots.txtファイルを確認し、最適化されていることを確認してください。このようにして、Googleやその他の重要な検索エンジンは、あなたがあなたのウェブサイトで世界に提供するすばらしいものすべてを「見る」ことができます。
![Windows 7またはVistaでActive Directory Windowsドメインに参加する[How-To]](/images/vista/join-an-active-directory-windows-domain-with-windows-7-or-vista-how-to.png)









コメントを残す