Vad är Robots.txt-filen på ett domän?

Ett av de största misstagen för nya webbplatsägare är inte att undersöka deras robots.txt-fil. Så vad är det ändå, och varför så viktigt? Vi har dina svar.
Om du äger en webbplats och bryr dig om din webbplatsSEO-hälsa, bör du göra dig mycket bekant med robots.txt-filen på din domän. Tro det eller inte, det är ett oroande stort antal människor som snabbt startar en domän, installerar en snabb WordPress-webbplats och aldrig bry sig om att göra någonting med deras robots.txt-fil.
Detta är farligt. En dåligt konfigurerad robots.txt-fil kan faktiskt förstöra webbplatsens SEO-hälsa och skada alla chanser du kan ha för att växa din trafik.
Vad är filen Robots.txt?
De Robots.txt filen heter lämpligt eftersom den i huvudsak är enfil som visar direktiv för webbrobotar (som sökmotorrobotar) om hur och vad de kan krypa på din webbplats. Detta har varit en webbstandard följt av webbplatser sedan 1994 och alla större webbcrawlers följer standarden.
Filen lagras i textformat (med en.txt-förlängning) i rotmappen på din webbplats. I själva verket kan du visa vilken webbplats som helst för robots.txt-filen bara genom att skriva domänen följt av /robots.txt. Om du försöker detta med groovyPost ser du ett exempel på en välstrukturerad robot.txt-fil.

Filen är enkel men effektiv. Den här exempelfilen skiljer inte mellan robotar. Kommandona utfärdas till alla robotar med hjälp av Användaragent: * direktiv. Detta betyder att alla kommandon som följer den gäller alla robotar som besöker webbplatsen för att genomsöka den.
Ange webbcrawlers
Du kan också ange specifika regler förspecifika webbsökare. Till exempel kanske du tillåter Googlebot (Googles webbcrawler) att genomsöka alla artiklar på din webbplats, men du kanske vill förhindra den ryska webcrawleren Yandex Bot från att genomsöka artiklar på din webbplats som har nedslående information om Ryssland.
Det finns hundratals webbsökare som söker på internet för information om webbplatser, men de 10 vanligaste du borde vara oroliga anges här.
- Googlebot: Googles sökmotor
- Bingbot: Microsofts Bing-sökmotor
- Sörpla: Yahoo sökmotor
- DuckDuckBot: DuckDuckGo sökmotor
- Baiduspider: Kinesisk Baidu-sökmotor
- YandexBot: Ryska Yandex sökmotor
- Exabot: Franska Exalead sökmotor
- Facebot: Facebooks krypande bot
- ia_archiver: Alexa's sökrobot för webbrankning
- MJ12bot: Stor länkindexdatabas
Ta exemplet ovan, om du villför att tillåta Googlebot att indexera allt på din webbplats, men ville blockera Yandex från att indexera ditt ryskbaserade artikelinnehåll, skulle du lägga till följande rader i din robots.txt-fil.
User-agent: googlebot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
User-agent: yandexbot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
Disallow: /russia/
Som du ser blockerar det första avsnittet baraGoogle från att genomsöka din WordPress-inloggningssida och administrativa sidor. Det andra avsnittet blockerar Yandex från samma, men också från hela området på din webbplats där du har publicerat artiklar med anti-Ryssland innehåll.
Detta är ett enkelt exempel på hur du kan använda Inte godkänna kommando för att kontrollera specifika webbsökare som besöker din webbplats.
Andra Robots.txt-kommandon
Disallow är inte det enda kommandot du har tillgång till i din robots.txt-fil. Du kan också använda något av de andra kommandona som styr hur en robot kan genomsöka din webbplats.
- Inte godkänna: Berättar användaragenten att undvika genomsökning av specifika webbadresser eller hela delar av din webbplats.
- Tillåta: Gör att du kan finjustera specifika sidor eller undermappar på din webbplats, även om du kanske har tillåtit en överordnad mapp. Till exempel kan du avvisa: / om /, men sedan tillåta: / om / ryan /.
- Crawl-fördröjning: Detta berättar sökroboten att vänta xx antal sekunder innan du börjar genomsöka webbplatsens innehåll.
- sitemap: Ange sökmotorer (Google, Ask, Bing och Yahoo) platsen för dina XML-webbplatskartor.
Tänk på att bots kommer endast lyssna på de kommandon du har angett när du anger botens namn.
Ett vanligt misstag som människor gör är att tillåta områden som / wp-admin / från alla bots, men ange sedan ett googlebot-avsnitt och endast tillåta andra områden (som / om /).
Eftersom bots bara följer de kommandon du anger i deras avsnitt, måste du ändra alla de andra kommandona du har angett för alla bots (med hjälp av * användaragenten).
- Inte godkänna: Kommandot användes för att berätta för en användaragent att inte krypa in en viss URL. Endast en "Disallow:" -rad är tillåten för varje URL.
- Tillåt (gäller endast för Googlebot): Kommandot att berätta för Googlebot att det kan komma åt en sida eller undermapp även om dess överordnade sida eller undermapp kan tillåtas.
- Crawl-fördröjning: Hur många sekunder ska en sökrobot vänta innan sidans innehåll laddas och genomsökas. Observera att Googlebot inte bekräftar detta kommando, men genomsökningshastigheten kan ställas in i Google Search Console.
- Sitemap: Används för att räkna ut platsen för en XML-webbplatskarta (er) som är kopplade till denna URL. Observera att detta kommando endast stöds av Google, Ask, Bing och Yahoo.
Tänk på att robots.txt är avsett att hjälpa legitima bots (som sökmotorbots) krypa din webbplats mer effektivt.
Det finns massor av besvärliga sökrobotar där utesom kryper din webbplats för att göra saker som att skrapa e-postadresser eller stjäla ditt innehåll. Om du vill försöka använda din robots.txt-fil för att blockera dessa sökrobotar från att genomsöka något på din webbplats, bry dig inte. Skaparna av dessa sökrobotar ignorerar vanligtvis allt du har lagt i din robots.txt-fil.
Varför avvisa någonting?
Att få Googles sökmotor att genomsöka så mycket kvalitetsinnehåll på din webbplats som möjligt är ett primärt problem för de flesta webbplatsägare.
Google expanderar emellertid endast en begränsad krypa budget och genomsökningshastighet på enskilda webbplatser. Genomsökningshastigheten är hur många förfrågningar per sekund Googlebot kommer att göra till din webbplats under genomsökningshändelsen.
Mer viktigt är genomsnittsbudgeten, vilket är hurmånga totala förfrågningar som Googlebot kommer att göra för att genomsöka din webbplats under en session. Google "spenderar" sin genomsnittsbudget genom att fokusera på områden på din webbplats som är mycket populära eller har förändrats nyligen.
Du är inte blind för den här informationen. Om du besöker Googles verktyg för webbansvariga kan du se hur sökroboten hanterar din webbplats.

Som du ser håller sökroboten sin aktivitet på din webbplats ganska konstant varje dag. Det kryper inte alla webbplatser, utan bara de som den anser vara de viktigaste.
Varför lämna det upp till Googlebot att bestämma vad som ärviktigt på din webbplats, när du kan använda din robots.txt-fil för att berätta vad de viktigaste sidorna är? Detta förhindrar att Googlebot slösar tid på sidor med lågt värde på din webbplats.
Optimera din genomsnittsbudget
Med Google Webmaster Tools kan du också kontrollera om Googlebot läser din robots.txt-fil bra och om det finns några fel.
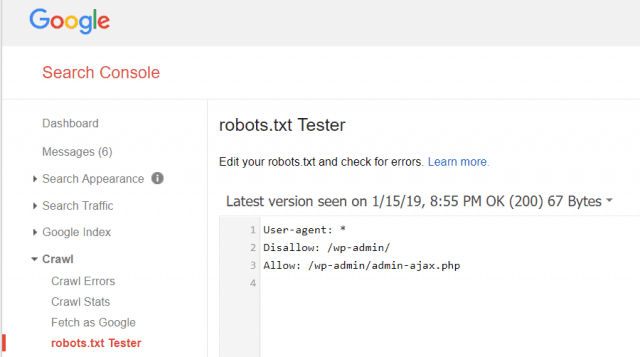
Detta hjälper dig att verifiera att du har strukturerat din robots.txt-fil korrekt.
Vilka sidor bör du inte tillåta från Googlebot? Det är bra för din webbplats SEO att inte tillåta följande sidor kategorier.
- Duplicera sidor (som skrivarvänliga sidor)
- Tacksidor som följer formulärbaserade order
- Beställnings- eller informationsfrågeformulär
- Kontaktsidor
- Inloggningssidor
- Leadmagnet "försäljning" -sidor
Ignorera inte din Robots.txt-fil
Det största misstaget som nya webbplatsägare gör ärtittar aldrig ens på deras robots.txt-fil. Den värsta situationen kan vara att robots.txt-filen faktiskt blockerar din webbplats, eller områden på din webbplats, från att få genomsökt alls.
Se till att granska din robots.txt-fil och se till att den är optimerad. På detta sätt "ser" Google och andra viktiga sökmotorer alla fantastiska saker du erbjuder världen med din webbplats.
![Gå med i en Active Directory Windows-domän med Windows 7 eller Vista [Hur du gör]](/images/vista/join-an-active-directory-windows-domain-with-windows-7-or-vista-how-to.png)









Lämna en kommentar