एक डोमेन में Robots.txt फ़ाइल क्या है?

नए वेबसाइट मालिकों के लिए सबसे बड़ी गलतियों में से एक उनके robots.txt फ़ाइल में नहीं दिख रही है। तो यह वैसे भी क्या है, और इतना महत्वपूर्ण क्यों है? आपके जवाब हमारे पास हैं।
यदि आप एक वेबसाइट के मालिक हैं और अपनी साइट के बारे में परवाह करते हैंएसईओ स्वास्थ्य, आपको अपने डोमेन पर robots.txt फ़ाइल से बहुत परिचित होना चाहिए। मानो या न मानो, कि एक अशांत उच्च संख्या वाले लोग हैं जो जल्दी से एक डोमेन लॉन्च करते हैं, एक त्वरित वर्डप्रेस वेबसाइट स्थापित करते हैं, और कभी भी अपने robots.txt फ़ाइल के साथ कुछ भी करने से परेशान नहीं करते हैं।
यह खतरनाक है। खराब तरीके से कॉन्फ़िगर किया गया robots.txt फ़ाइल वास्तव में आपकी साइट के एसईओ स्वास्थ्य को नष्ट कर सकती है, और आपके ट्रैफ़िक को बढ़ाने के लिए आपके पास मौजूद किसी भी मौके को नुकसान पहुंचा सकती है।
Robots.txt File क्या है?
The Robots.txt फ़ाइल को उपयुक्त रूप से नामित किया गया है क्योंकि यह अनिवार्य रूप से एक फ़ाइल है जो वेब रोबोटों (जैसे खोज इंजन रोबोटों) के लिए निर्देशों को सूचीबद्ध करती है कि वे आपकी वेबसाइट पर कैसे और क्या क्रॉल कर सकते हैं।यह 1 99 4 से वेबसाइटों द्वारा एक वेब मानक रहा है और सभी प्रमुख वेब क्रॉलर मानक का पालन करते हैं।
फ़ाइल को आपकी वेबसाइट के रूट फ़ोल्डर पर टेक्स्ट फॉर्मेट (.txt एक्सटेंशन के साथ) में संग्रहीत किया जाता है।वास्तव में, आप किसी भी वेबसाइट की robot.txt फ़ाइल को केवल डोमेन टाइप करके देख सकते हैं जिसके बाद/robots.txt।यदि आप इसे ग्रूमीपोस्ट के साथ आज़माते हैं, तो आपको एक अच्छी तरह से संरचित robot.txt फ़ाइल का एक उदाहरण दिखाई देगा।

फ़ाइल सरल लेकिन प्रभावी है। यह उदाहरण फ़ाइल रोबोटों के बीच अंतर नहीं करती है।आदेश का उपयोग करके सभी रोबोटों को जारी किए जाते हैं उपयोगकर्ता-एजेंट: * निर्देश. इसका मतलब यह है कि इसका पालन करने वाले सभी आदेश सभी रोबोटों पर लागू होते हैं जो इसे क्रॉल करने के लिए साइट पर जाते हैं।
वेब क्रॉलर्स निर्दिष्ट करना
आप विशिष्ट वेब क्रॉलर्स के लिए विशिष्ट नियम भी निर्दिष्ट कर सकते हैं।उदाहरण के लिए, आप Googlebot (Google के वेब क्रॉलर) को अपनी साइट पर सभी लेखों को क्रॉल करने की अनुमति दे सकते हैं, लेकिन आप रूसी वेब क्रॉलर यांडेक्स बॉट को अपनी साइट पर लेख क्रॉल करने से अस्वीकार कर सकते हैं, जिनके पास रूस के बारे में जानकारी को अपमानजनक है।
सैकड़ों वेब क्रॉलर हैं जो वेबसाइटों के बारे में जानकारी के लिए इंटरनेट को परिमार्जन करते हैं, लेकिन आपको जिन 10 सबसे आम के बारे में चिंतित होना चाहिए, वे यहां सूचीबद्ध हैं।
- Googlebot: गूगल सर्च इंजन
- बिंगबॉट: माइक्रोसॉफ्ट के बिंग सर्च इंजन
- Slurp: याहू खोज इंजन
- डकडकबोट: डकडकडगो सर्च इंजन
- ड्यूस्पाइडर: चीनी ड्यू खोज इंजन
- यांडेक्सबॉट: रूसी Yandex खोज इंजन
- एक्साबोट: फ्रेंच एक्सलेड सर्च इंजन
- फेसबॉट: फेसबुक के रेंगने बॉट
- ia_archiver: एलेक्सा की वेब रैंकिंग क्रॉलर
- MJ12bot: बड़े लिंक इंडेक्सिंग डेटाबेस
ऊपर उदाहरण परिदृश्य लेते हुए, यदि आप Googlebot को अपनी साइट पर सब कुछ इंडेक्स करने की अनुमति देना चाहते थे, लेकिन अपनी रूसी आधारित लेख सामग्री को अनुक्रमित करने से यांडेक्स को ब्लॉक करना चाहते थे, तो आप अपनी robots.txt फ़ाइल में निम्नलिखित पंक्तियां जोड़ना चाहते हैं।
User-agent: googlebot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
User-agent: yandexbot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
Disallow: /russia/
जैसा कि आप देख सकते हैं, पहला अनुभाग केवल Google को आपके वर्डप्रेस लॉगिन पेज और प्रशासनिक पृष्ठों को क्रॉल करने से रोकता है.दूसरा खंड Yandex को उसी से ब्लॉक करता है, लेकिन आपकी साइट के पूरे क्षेत्र से भी जहां आपने रूस विरोधी सामग्री के साथ लेख प्रकाशित किए हैं।
यह इस बात का एक सरल उदाहरण है कि आप कैसे उपयोग कर सकते हैं अस्वीकृत आपकी वेबसाइट पर जाने वाले विशिष्ट वेब क्रॉलर्स को नियंत्रित करने का आदेश।
अन्य रोबोट.txt कमांड
डिलो एकमात्र आदेश नहीं है जो आपके पास अपने robots.txt फ़ाइल में पहुंच है।आप किसी भी अन्य कमांड का भी उपयोग कर सकते हैं जो निर्देशित करेगा कि रोबोट आपकी साइट को कैसे क्रॉल कर सकता है।
- अस्वीकृत: उपयोगकर्ता-एजेंट को विशिष्ट यूआरएल, या आपकी साइट के पूरे वर्गों को क्रॉल करने से बचने के लिए कहता है।
- अनुमति: आपको अपनी साइट पर विशिष्ट पृष्ठों या सबफोल्डर को ठीक करने की अनुमति देता है, भले ही आपने माता-पिता के फ़ोल्डर को अस्वीकार कर दिया हो।उदाहरण के लिए, आप अस्वीकार कर सकते हैं: /के बारे में/, लेकिन फिर अनुमति: /about/ryan/।
- क्रॉल-देरी: यह क्रॉलर को साइट की सामग्री को क्रॉल करने के लिए शुरू करने से पहले सेकंड के xx संख्या इंतजार करने के लिए कहता है।
- साइटमैप: अपने एक्सएमएल साइटमैप्स का स्थान खोज इंजन (Google, पूछो, बिंग और याहू) प्रदान करें।
ध्यान रखें कि बॉट होगा ओन्ली जब आप बीओटी का नाम निर्दिष्ट करते हैं तो आपके द्वारा प्रदान किए गए आदेशों को सुनें।
एक आम गलती लोगों को सभी बॉट से /wp-व्यवस्थापक/जैसे क्षेत्रों की अनुमति नहीं है, लेकिन फिर एक googlebot अनुभाग निर्दिष्ट और केवल अंय क्षेत्रों (जैसे/के बारे में/) की अनुमति नहीं है ।
चूंकि बॉट केवल उन आदेशों का पालन करते हैं जो आपके द्वारा उनके अनुभाग में निर्दिष्ट करते हैं, इसलिए आपको उन सभी अन्य आदेशों को फिर से बताना होगा जो आपने सभी बॉट (* उपयोगकर्ता-एजेंट का उपयोग करके) के लिए निर्दिष्ट किए हैं।
- अस्वीकृत: कमांड एक उपयोगकर्ता-एजेंट को विशेष यूआरएल क्रॉल न करने के लिए कहता था।प्रत्येक यूआरएल के लिए केवल एक "डिलो:" लाइन की अनुमति है।
- अनुमति दें (केवल Googlebot के लिए लागू): Googlebot को बताने का आदेश यह किसी पृष्ठ या सबफोल्डर तक पहुंच सकता है, भले ही इसके मूल पृष्ठ या सबफोल्डर को अस्वीकार किया जा सकता है।
- क्रॉल-देरी: पेज सामग्री लोड करने और क्रॉल करने से पहले क्रॉलर को कितने सेकंड इंतजार करना चाहिए।ध्यान दें कि Googlebot इस आदेश को स्वीकार नहीं करता है, लेकिन क्रॉल दर Google खोज कंसोल में सेट की जा सकती है.
- साइटमैप: इस यूआरएल से जुड़े एक्सएमएल साइटमैप (एस) के स्थान को कॉल करने के लिए उपयोग किया जाता है।नोट यह आदेश केवल Google, पूछो, बिंग और याहू द्वारा समर्थित है।
ध्यान रखें कि robots.txt वैध बॉट (जैसे खोज इंजन बॉट) आपकी साइट को अधिक प्रभावी ढंग से क्रॉल करने में मदद करने के लिए है।
बहुत सारे नापाक क्रॉलर हैं जो आपकी साइट को ईमेल पते को कुरेदने या आपकी सामग्री चुराने जैसी चीजें करने के लिए क्रॉल कर रहे हैं।यदि आप अपनी साइट पर कुछ भी क्रॉल करने से उन क्रॉलर्स को ब्लॉक करने के लिए अपनी robots.txt फ़ाइल का प्रयास करना चाहते हैं, तो परेशान न हों।उन क्रॉलर्स के रचनाकार आमतौर पर आपके द्वारा अपनी robots-txt फ़ाइल में रखी गई किसी भी चीज़ को अनदेखा करते हैं।
कुछ भी अस्वीकार क्यों?
Google के खोज इंजन को अपनी वेबसाइट पर जितना संभव हो उतना गुणवत्ता वाली सामग्री क्रॉल करना अधिकांश वेबसाइट मालिकों के लिए एक प्राथमिक चिंता का विषय है।
हालांकि, गूगल केवल एक सीमित व्यय क्रॉल बजट तथा क्रॉल रेट अलग-अलग साइटों पर। क्रॉल दर है कि रेंगने की घटना के दौरान प्रति सेकंड Googlebot आपकी साइट पर कितने अनुरोध करेंगे।
क्रॉल बजट अधिक महत्वपूर्ण है, जो यह है कि Googlebot आपकी साइट को एक सत्र में क्रॉल करने के लिए कितने कुल अनुरोध करेंगे।Google आपकी साइट के उन क्षेत्रों पर ध्यान केंद्रित करके अपने क्रॉल बजट को "खर्च करता है" जो बहुत लोकप्रिय हैं या हाल ही में बदल गए हैं।
आप इस जानकारी के लिए अंधा नहीं कर रहे हैं । अगर आप Google वेबमास्टर टूल्स पर जाते हैं, तो आप देख सकते हैं कि क्रॉलर आपकी साइट को कैसे संभाल रहा है.

जैसा कि आप देख सकते हैं, क्रॉलर आपकी साइट पर गतिविधि को हर दिन बहुत स्थिर रखता है।यह सभी साइटों को क्रॉल नहीं करता है, लेकिन केवल वे ही इसे सबसे महत्वपूर्ण मानते हैं।
यह तय करने के लिए Googlebot पर क्यों छोड़ दें कि आपकी साइट पर क्या महत्वपूर्ण है, जब आप अपनी robots.txt फ़ाइल का उपयोग यह बताने के लिए कर सकते हैं कि सबसे महत्वपूर्ण पृष्ठ क्या हैं?यह Googlebot को आपकी साइट पर कम मूल्य वाले पृष्ठों पर समय बर्बाद करने से रोकदेगा।
अपने क्रॉल बजट का अनुकूलन
Google वेबमास्टर टूल आपको यह भी जांचने देता है कि Googlebot आपके robotsों को पढ़ रहा है या नहीं। txt फ़ाइल ठीक है और क्या कोई त्रुटि है।
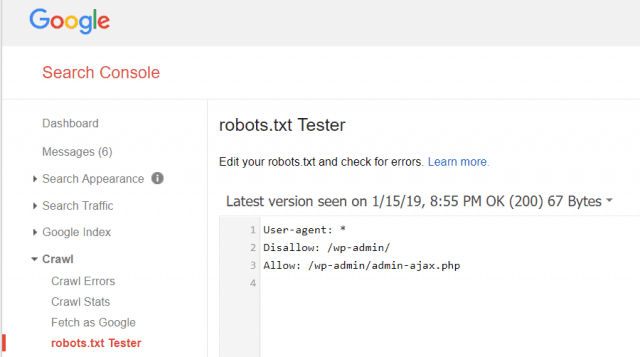
यह आपको यह सत्यापित करने में मदद करता है कि आपने अपनी रोबोट.txt फ़ाइल को सही ढंग से संरचित किया है।
आपको Googlebot से किन पृष्ठों को अस्वीकार करना चाहिए? आपकी साइट एसईओ के लिए पृष्ठों की निम्नलिखित श्रेणियों को अस्वीकार करना अच्छा है।
- डुप्लीकेट पेज (प्रिंटर के अनुकूल पेज की तरह)
- फॉर्म-आधारित आदेशों का पालन करने वाले पृष्ठों का धन्यवाद
- ऑर्डर या जानकारी क्वेरी फ़ीस
- संपर्क पृष्ठ
- लॉगिन पेज
- लीड चुंबक "बिक्री" पृष्ठ
अपनी Robots.txt फ़ाइल को अनदेखा न करें
सबसे बड़ी गलती नई वेबसाइट मालिकों बनाने के लिए भी अपने robots.txt फ़ाइल को देख कभी नहीं है ।सबसे बुरी स्थिति यह हो सकती है कि robots.txt फ़ाइल वास्तव में आपकी साइट या आपकी साइट के क्षेत्रों को अवरुद्ध कर रही है, जो बिल्कुल क्रॉल होने से है।
अपने robots.txt फ़ाइल की समीक्षा करना सुनिश्चित करें और यह सुनिश्चित करें कि यह अनुकूलित है।इस तरह, Google और अन्य महत्वपूर्ण खोज इंजन आपकी वेबसाइट के साथ दुनिया को प्रदान करने वाली सभी शानदार चीजों को "देखें"।
![Windows 7 या Vista [हाउ-टू] के साथ एक सक्रिय निर्देशिका विंडोज डोमेन में शामिल हों](/images/vista/join-an-active-directory-windows-domain-with-windows-7-or-vista-how-to.png)









एक टिप्पणी छोड़ें