Was ist die Robots.txt-Datei in einer Domain?

Einer der größten Fehler für neue Website-Besitzer ist, nicht in ihre robots.txt-Datei zu schauen. Also, was ist das überhaupt und warum so wichtig? Wir haben Ihre Antworten.
Wenn Sie eine Website besitzen und sich um Ihre Website kümmernSEO Gesundheit, sollten Sie sich mit der robots.txt-Datei auf Ihrer Domain sehr vertraut machen. Ob Sie es glauben oder nicht, das ist eine beunruhigend hohe Anzahl von Menschen, die schnell eine Domain eröffnen, eine schnelle WordPress-Website installieren und sich nie die Mühe machen, etwas mit ihrer robots.txt-Datei zu tun.
Das ist gefährlich. Eine schlecht konfigurierte robots.txt-Datei kann die SEO-Integrität Ihrer Website tatsächlich zerstören und die Wahrscheinlichkeit verringern, dass Ihr Datenverkehr wächst.
Was ist die Robots.txt-Datei?
Das Robots.txt Datei trägt den passenden Namen, da es sich im Wesentlichen um eineDatei, in der Anweisungen für die Webroboter (wie Suchmaschinenroboter) aufgeführt sind, wie und was sie auf Ihrer Website crawlen können. Dies ist seit 1994 ein Web-Standard, dem Websites folgen, und alle wichtigen Web-Crawler halten sich an diesen Standard.
Die Datei wird im Textformat gespeichert (mit einem.txt extension) im Stammverzeichnis Ihrer Website. Sie können die robot.txt-Datei jeder Website anzeigen, indem Sie einfach die Domäne gefolgt von /robots.txt eingeben. Wenn Sie dies mit groovyPost versuchen, sehen Sie ein Beispiel für eine gut strukturierte robot.txt-Datei.

Die Datei ist einfach, aber effektiv. Diese Beispieldatei unterscheidet nicht zwischen Robotern. Die Befehle werden an alle Roboter unter Verwendung des Befehls ausgegeben User-Agent: * Richtlinie. Dies bedeutet, dass alle darauf folgenden Befehle auf alle Roboter angewendet werden, die die Site besuchen, um sie zu crawlen.
Angeben von Web-Crawlern
Sie können auch bestimmte Regeln für angebenbestimmte Web-Crawler. Sie können beispielsweise zulassen, dass Googlebot (der Webcrawler von Google) alle Artikel auf Ihrer Website crawlt. Möglicherweise möchten Sie jedoch dem russischen Webcrawler Yandex Bot das Crawlen von Artikeln auf Ihrer Website untersagen, die abfällige Informationen zu Russland enthalten.
Es gibt Hunderte von Webcrawlern, die das Internet nach Informationen über Websites durchsuchen. Die 10 häufigsten Probleme, die Sie haben sollten, sind hier aufgelistet.
- Googlebot: Google-Suchmaschine
- Bingbot: Die Bing-Suchmaschine von Microsoft
- Schlürfen: Yahoo-Suchmaschine
- DuckDuckBot: DuckDuckGo Suchmaschine
- Baiduspider: Chinesische Baidu-Suchmaschine
- YandexBot: Russische Yandex-Suchmaschine
- Exabot: Französische Exalead-Suchmaschine
- Facebot: Der Crawling-Bot von Facebook
- ia_archiver: Alexa's Webranking-Crawler
- MJ12bot: Große Datenbank für die Link-Indizierung
Nehmen Sie das obige Beispielszenario, wenn Sie wolltenDamit Googlebot alles auf Ihrer Website indizieren kann, Yandex jedoch die Indizierung Ihres auf Russisch basierenden Artikelinhalts verhindern soll, fügen Sie Ihrer robots.txt-Datei die folgenden Zeilen hinzu.
User-agent: googlebot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
User-agent: yandexbot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
Disallow: /russia/
Wie Sie sehen können, blockiert der erste Abschnitt nurGoogle crawlt Ihre WordPress-Anmeldeseite und Verwaltungsseiten nicht. Der zweite Abschnitt sperrt Yandex vor demselben, aber auch vor dem gesamten Bereich Ihrer Website, in dem Sie Artikel mit Anti-Russland-Inhalten veröffentlicht haben.
Dies ist ein einfaches Beispiel für die Verwendung von Verbieten Befehl zum Steuern bestimmter Webcrawler, die Ihre Website besuchen.
Andere Robots.txt-Befehle
Disallow ist nicht der einzige Befehl, auf den Sie in Ihrer robots.txt-Datei zugreifen können. Sie können auch einen der anderen Befehle verwenden, mit denen gesteuert wird, wie ein Roboter Ihre Site crawlen kann.
- Verbieten: Weist den Benutzeragenten an, das Crawlen bestimmter URLs oder ganzer Abschnitte Ihrer Website zu vermeiden.
- ermöglichen: Ermöglicht die Feinabstimmung bestimmter Seiten oder Unterordner auf Ihrer Site, auch wenn Sie möglicherweise einen übergeordneten Ordner nicht zugelassen haben. Sie können beispielsweise / about / nicht zulassen, dann aber / about / ryan / zulassen.
- Crawl-Verzögerung: Hiermit wird der Crawler angewiesen, xx Sekunden zu warten, bevor mit dem Crawlen des Websiteinhalts begonnen wird.
- Seitenverzeichnis: Stellen Sie Suchmaschinen (Google, Ask, Bing und Yahoo) den Speicherort Ihrer XML-Sitemaps bereit.
Denken Sie daran, dass Bots dies tun nur Hören Sie sich die Befehle an, die Sie angegeben haben, wenn Sie den Namen des Bots angeben.
Ein häufiger Fehler ist, Bereiche wie / wp-admin / von allen Bots auszuschließen, dann aber einen Googlebot-Bereich anzugeben und nur andere Bereiche (wie / about /) auszuschließen.
Da Bots nur den Befehlen folgen, die Sie in ihrem Abschnitt angegeben haben, müssen Sie alle anderen Befehle, die Sie für alle Bots angegeben haben, erneut ausführen (mithilfe des * user-agents).
- Verbieten: Der Befehl, mit dem ein Benutzeragent angewiesen wird, bestimmte URLs nicht zu crawlen. Für jede URL ist nur eine Zeile "Disallow:" zulässig.
- Zulassen (gilt nur für Googlebot): Der Befehl, mit dem Googlebot angewiesen wird, auf eine Seite oder einen Unterordner zuzugreifen, obwohl die übergeordnete Seite oder der übergeordnete Unterordner möglicherweise nicht zulässig sind.
- Crawl-Verzögerung: Wie viele Sekunden sollte ein Crawler warten, bevor Seiteninhalte geladen und gecrawlt werden. Beachten Sie, dass der Googlebot diesen Befehl nicht bestätigt, die Crawling-Rate jedoch in der Google Search Console festgelegt werden kann.
- Seitenverzeichnis: Dient zum Abrufen des Speicherorts einer XML-Sitemap, die mit dieser URL verknüpft ist. Beachten Sie, dass dieser Befehl nur von Google, Ask, Bing und Yahoo unterstützt wird.
Denken Sie daran, dass robots.txt legitimen Bots (wie Suchmaschinen-Bots) dabei helfen soll, Ihre Website effektiver zu crawlen.
Es gibt viele schändliche Crawler da draußendie Ihre Website crawlen, um beispielsweise E-Mail-Adressen zu kratzen oder Ihren Inhalt zu stehlen. Wenn Sie versuchen möchten, mithilfe Ihrer robots.txt-Datei zu verhindern, dass diese Crawler etwas auf Ihrer Website crawlen, stören Sie sich nicht. Die Ersteller dieser Crawler ignorieren normalerweise alles, was Sie in Ihre robots.txt-Datei eingefügt haben.
Warum etwas verbieten?
Die Suchmaschine von Google dazu zu bringen, so viele hochwertige Inhalte wie möglich auf Ihrer Website zu crawlen, ist für die meisten Websitebesitzer ein Hauptanliegen.
Google gibt jedoch nur eine begrenzte Menge aus Crawling-Budget und Crawling-Rate auf einzelnen Seiten. Die Durchforstungsrate gibt an, wie viele Anfragen pro Sekunde Googlebot während des Durchforstungsereignisses an Ihre Website sendet.
Wichtiger ist das Crawling-Budget, also wieViele Anfragen, die Googlebot insgesamt stellt, um Ihre Website in einer Sitzung zu crawlen. Google gibt sein Crawling-Budget aus, indem es sich auf Bereiche Ihrer Website konzentriert, die sehr beliebt sind oder sich in letzter Zeit geändert haben.
Sie sind für diese Informationen nicht blind. Wenn Sie die Google Webmaster-Tools besuchen, können Sie sehen, wie der Crawler Ihre Website verarbeitet.

Wie Sie sehen, bleibt die Aktivität des Crawlers auf Ihrer Website jeden Tag ziemlich konstant. Es werden nicht alle Websites gecrawlt, sondern nur die, die es für am wichtigsten hält.
Warum überlässt man es Googlebot, zu entscheiden, was passiert?wichtig auf Ihrer Website, wann können Sie Ihre robots.txt-Datei verwenden, um zu sagen, was die wichtigsten Seiten sind? Dadurch wird verhindert, dass Googlebot Zeit auf Seiten mit geringem Wert auf Ihrer Website verschwendet.
Optimieren Sie Ihr Crawling-Budget
Mit den Google Webmaster-Tools können Sie auch überprüfen, ob Googlebot Ihre robots.txt-Datei korrekt liest und ob Fehler vorliegen.
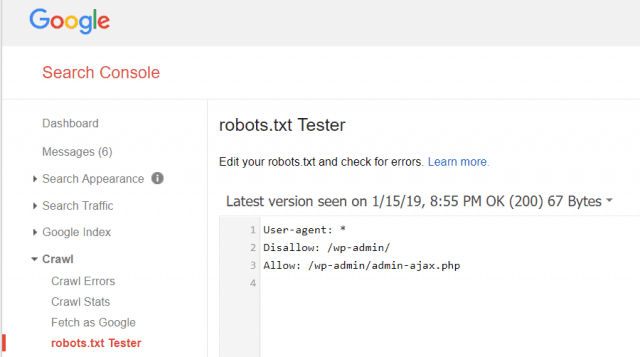
Auf diese Weise können Sie überprüfen, ob Sie Ihre robots.txt-Datei richtig strukturiert haben.
Welche Seiten sollten Sie für Googlebot nicht zulassen? Es ist gut, wenn Ihre Website-SEO die folgenden Seitenkategorien nicht zulässt.
- Doppelte Seiten (wie druckerfreundliche Seiten)
- Vielen Dank Seiten nach formularbasierten Bestellungen
- Bestell- oder Informationsanfrageformulare
- Kontaktseiten
- Anmeldeseiten
- Verkaufsseiten mit Bleimagneten
Ignorieren Sie Ihre Robots.txt-Datei nicht
Der größte Fehler, den neue Website-Besitzer machen, istSehen Sie sich niemals die robots.txt-Datei an. Die schlimmste Situation könnte sein, dass die robots.txt-Datei Ihre Website oder Bereiche Ihrer Website tatsächlich daran hindert, überhaupt gecrawlt zu werden.
Überprüfen Sie unbedingt Ihre robots.txt-Datei und stellen Sie sicher, dass sie optimiert ist. Auf diese Weise „sehen“ Google und andere wichtige Suchmaschinen all die fantastischen Dinge, die Sie der Welt mit Ihrer Website bieten.
![Beitritt zu einer Active Directory-Windows-Domäne unter Windows 7 oder Vista [How-To]](/images/vista/join-an-active-directory-windows-domain-with-windows-7-or-vista-how-to.png)









Hinterlasse einen Kommentar