Kas ir Robots.txt fails domēnā?

Viena no lielākajām jauno vietņu īpašnieku kļūdām nav viņu robots.txt faila izpētīšana. Kas tas tik un tā ir, kāpēc tas ir tik svarīgi? Mums ir jūsu atbildes.
Ja jums pieder vietne un jums rūp jūsu vietneSEO veselība, jums vajadzētu ļoti labi iepazīties ar sava domēna failu robots.txt. Ticiet vai nē, tas ir satraucoši liels skaits cilvēku, kuri ātri palaiž domēnu, instalē ātru WordPress vietni un nekad neuztraucas neko darīt ar savu robots.txt failu.
Tas ir bīstami. Vāji konfigurēts fails robots.txt faktiski var iznīcināt jūsu vietnes SEO veselību un sabojāt visas iespējamās datplūsmas palielināšanas iespējas.
Kas ir fails Robots.txt?
Uz Robots.txt fails ir pareizi nosaukts, jo tas būtībā ir afails, kurā uzskaitītas tīmekļa robotu (piemēram, meklētājprogrammu robotu) direktīvas par to, kā un ko viņi var pārmeklēt jūsu vietnē. Šis ir tīmekļa standarts, kuru kopš 1994. gada seko vietnes, un visi lielākie tīmekļa roboti ievēro šo standartu.
Fails tiek glabāts teksta formātā (ar.txt paplašinājums) jūsu vietnes saknes mapē. Faktiski jūs varat apskatīt jebkuras vietnes robot.txt failu, vienkārši ierakstot domēnu, kam seko /robots.txt. Ja izmēģināt to ar groovyPost, redzēsit labi strukturēta robot.txt faila piemēru.

Fails ir vienkāršs, bet efektīvs. Šis faila piemērs nenošķir robotus. Komandas tiek izsniegtas visiem robotiem, izmantojot Lietotāja aģents: * direktīva. Tas nozīmē, ka visas komandas, kas tai seko, attiecas uz visiem robotiem, kuri apmeklē vietni, lai to pārmeklētu.
Tīkla rāpuļprogrammu norādīšana
Jūs varētu arī norādīt īpašus noteikumuskonkrēti tīmekļa rāpuļprogrammas. Piemēram, jūs varētu ļaut Googlebot (Google tīmekļa rāpuļprogrammai) pārmeklēt visus jūsu vietnes rakstus, taču jūs varētu vēlēties, lai krievu tīmekļa rāpuļprogramma Yandex Bot varētu pārmeklēt jūsu vietnē rakstus, kuros ir nepatīkama informācija par Krieviju.
Ir simtiem tīmekļa rāpuļprogrammu, kas meklē informāciju par vietnēm internetā, taču šeit ir uzskaitīti 10 visbiežāk sastopamie, par kuriem jums vajadzētu uztraukties.
- Googlebot: Google meklētājprogramma
- Bingbots: Microsoft meklētājprogramma Bing
- Slurp: Yahoo meklētājprogramma
- DuckDuckBot: Meklētājprogramma DuckDuckGo
- Baiduspider: Ķīniešu Baidu meklētājprogramma
- YandexBot: Krievu Yandex meklētājprogramma
- Exabot: Meklētājprogramma Exalead franču valodā
- Facebot: Facebook pārmeklē robotu
- ia_archiver: Alexa tīmekļa rangu rāpuļprogramma
- MJ12bot: Liela saišu indeksācijas datu bāze
Izmantojot iepriekš minēto scenāriju, ja vēlatieslai ļautu Googlebot indeksēt visu jūsu vietnē, bet vēlējās bloķēt Yandex indeksēt jūsu krievu valodas rakstu saturu, savam robots.txt failam pievienojiet šādas rindas:
User-agent: googlebot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
User-agent: yandexbot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
Disallow: /russia/
Kā redzat, pirmā sadaļa tikai bloķējasGoogle pārmeklē jūsu WordPress pieteikšanās lapu un administratīvās lapas. Otrajā sadaļā tiek bloķēts Yandex gan no tā paša, gan arī no visa jūsu vietnes apgabala, kurā esat publicējis rakstus ar anti-Krievijas saturu.
Šis ir vienkāršs piemērs, kā izmantot Neatļaut komanda, lai kontrolētu noteiktus tīmekļa rāpuļprogrammas, kas apmeklē jūsu vietni.
Citas robots.txt komandas
Neatļaut nav vienīgā komanda, kurai esat piekļuvis failā robots.txt. Varat arī izmantot jebkuru citu komandu, kas norādīs, kā robots var pārmeklēt jūsu vietni.
- Neatļaut: Pasaka lietotāja aģentam, lai izvairītos no noteiktu URL vai visu jūsu vietnes sadaļu pārmeklēšanas.
- Atļaut: Ļauj precizēt noteiktas vietnes lapas vai apakšmapes, pat ja jūs, iespējams, esat atļāvis vecāku mapi. Piemēram, jūs varat neļaut: / about /, bet pēc tam atļaut: / about / ryan /.
- Pārmeklēšana - kavēšanās: Tas rāpuļprogrammai liek nogaidīt xx sekunžu skaitu, pirms sākt rāpot vietnes saturu.
- Vietnes karte: Nodrošiniet meklētājprogrammām (Google, Ask, Bing un Yahoo) savu XML vietņu karšu atrašanās vietu.
Paturiet prātā, ka roboti būs tikai klausieties komandas, kuras esat sniedzis, kad norādāt robotprogrammatūras vārdu.
Bieži pieļauta kļūda, kas tiek pieļauta, aizliedzot tādus apgabalus kā / wp-admin / no visiem robotiem, bet pēc tam norādiet sadaļu googlebot un tikai citu apgabalu (piemēram, / par /) aizliegšanu.
Tā kā robotprogrammatūras seko tikai tām komandām, kuras jūs norādāt to sadaļā, jums ir jāpārskata visas pārējās komandas, kuras esat norādījis visiem robotprogrammatūrām (izmantojot * user-agent).
- Neatļaut: Komanda, ko izmanto, lai norādītu lietotāja aģentam nepārmeklēt noteiktu URL. Katrā URL ir atļauta tikai viena rindiņa “Neatļaut:”.
- Atļaut (attiecas tikai uz Googlebot): Komanda, lai paziņotu Googlebot, ka tā var piekļūt lapai vai apakšmapei, pat ja tās mātes lapa vai apakšmape var tikt aizliegta.
- Pārmeklēšana - kavēšanās: Cik sekundes rāpuļprogrammai jāgaida, pirms tiek ielādēts un pārmeklēts lapas saturs. Ņemiet vērā, ka Googlebot neatzīst šo komandu, bet pārmeklēšanas ātrumu var iestatīt Google meklēšanas konsolē.
- Vietnes karte: Izmanto, lai izsauktu ar šo URL saistītās XML vietnes kartes (-u) atrašanās vietu. Ņemiet vērā, ka šo komandu atbalsta tikai Google, Ask, Bing un Yahoo.
Ņemiet vērā, ka robots.txt ir paredzēts, lai palīdzētu likumīgiem robotprogrammatūras (piemēram, meklētājprogrammu robotprogrammatūras) efektīvāk pārmeklēt jūsu vietni.
Tur ir daudz negodīgu rāpuļprogrammukas pārmeklē jūsu vietni, lai veiktu citas darbības, piemēram, nokasītu e-pasta adreses vai nozagtu jūsu saturu. Neuztraucieties, ja vēlaties izmēģināt un izmantot failu robots.txt, lai šie rāpuļprogrammas neļautu kaut ko pārmeklēt jūsu vietnē. Šo rāpuļprogrammu veidotāji parasti ignorē visu, ko esat ievietojis failā robots.txt.
Kāpēc kaut ko neatļaut?
Lielākā vietņu īpašnieku galvenā problēma ir panākt, lai Google meklētājprogramma pārmeklētu pēc iespējas vairāk kvalitatīva satura jūsu vietnē.
Tomēr Google tērē tikai ierobežotu summu pārmeklēt budžetu un pārmeklēšanas ātrums atsevišķās vietnēs. Pārmeklēšanas ātrums ir atkarīgs no tā, cik pieprasījumus sekundē Googlebot jūsu vietnei sniegs pārmeklēšanas notikuma laikā.
Daudz svarīgāks ir pārmeklēšanas budžets, kā tas irdaudz kopēju pieprasījumu, ko Googlebot veiks, lai pārmeklētu jūsu vietni vienā sesijā. Google “tērē” pārmeklēšanas budžetu, koncentrējoties uz jūsu vietnes jomām, kas ir ļoti populāras vai nesen mainījušās.
Šī informācija jums nav akla. Ja apmeklējat Google tīmekļa pārziņa rīkus, varat redzēt, kā rāpuļprogramma rīkojas ar jūsu vietni.

Kā redzat, kāpurķēžu darbība jūsu vietnē katru dienu notiek diezgan nemainīgi. Tas nepārmeklē visas vietnes, bet tikai tās, kuras tā uzskata par vissvarīgākajām.
Kāpēc izvēlēties Googlebot, lai izlemtu, kas tas irir svarīgi jūsu vietnē, kad varat izmantot failu robots.txt, lai pateiktu, kas ir vissvarīgākās lapas? Tas neļaus Googlebot tērēt laiku mazvērtīgām jūsu vietnes lapām.
Pārmeklēšanas budžeta optimizēšana
Google tīmekļa pārziņa rīki arī ļauj jums pārbaudīt, vai Googlebot nolasa jūsu robots.txt failu un vai tajā nav kļūdu.
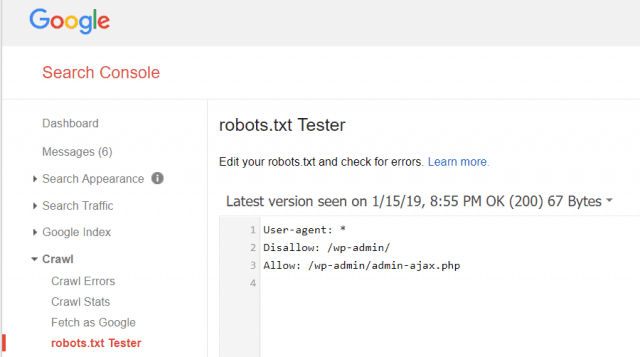
Tas palīdz jums pārbaudīt, vai robots.txt fails ir pareizi strukturēts.
Kādas lapas jums vajadzētu aizliegt no Googlebot? Jūsu vietnes SEO ir ieteicams aizliegt šādu kategoriju lapas.
- Dublikātu lapas (piemēram, drukāšanai piemērotas lapas)
- Paldies lapām, kas seko pēc veidlapām balstītiem pasūtījumiem
- Pasūtījuma vai informācijas vaicājuma veidlapas
- Kontaktinformācijas lapas
- Pieteikšanās lapas
- Svina magnēta “pārdošanas” lapas
Neignorējiet savu failu Robots.txt
Lielākā jauno vietņu īpašnieku kļūda irnekad pat neskatās viņu failu robots.txt. Sliktākā situācija varētu būt tāda, ka fails robots.txt faktiski bloķē jūsu vietnes vai vietnes teritoriju vispārēju pārmeklēšanu.
Pārbaudiet failu robots.txt un pārliecinieties, ka tas ir optimizēts. Tādā veidā Google un citas svarīgas meklētājprogrammas “redz” visas pasakainās lietas, ko piedāvājat pasaulei ar savu vietni.
![Pievienojieties aktīvās direktorijas Windows domēnam ar Windows 7 vai Vista [Padomi]](/images/vista/join-an-active-directory-windows-domain-with-windows-7-or-vista-how-to.png)









Atstājiet savu komentāru