Mi a domainben a Robots.txt fájl?

Az új webhelyek tulajdonosai számára az egyik legnagyobb hiba az, hogy nem vizsgálják meg a robots.txt fájlt. Szóval mi ez egyébként, és miért olyan fontos? Megvan a válaszod.
Ha egy webhelyed van, és érdekli a webhelyétA SEO-állapot szempontjából nagyon jól ismerje meg magát a domain robots.txt fájljával. Hidd el vagy sem, ezek zavaróan nagy számú ember, aki gyorsan elindít egy domaint, telepít egy gyors WordPress webhelyet, és soha nem zavarja semmit a robots.txt fájllal.
Ez veszélyes. A rosszul konfigurált robots.txt fájl valójában tönkreteheti webhelye SEO állapotát, és károsíthatja a forgalom növekedésével kapcsolatos esélyeit.
Mi az a Robots.txt fájl?
A Robots.txt a fájlt helyesen nevezték el, mert lényegében afájl, amely felsorolja az internetes robotok (például a keresőmotorok robotjai) irányelveit arról, hogy miként és mit tudnak feltérképezni az Ön webhelyén. Ez egy webes szabvány, amelyet 1994 óta követnek a weboldalak, és az összes nagyobb webrobot betartja a szabványt.
A fájlt szöveges formátumban tárolja (a.txt kiterjesztés) a webhely gyökérmappájában. Valójában bármilyen weboldal robot.txt fájlt megnézhet, csak a /robots.txt követő domain beírásával. Ha ezt a groovyPost programmal próbálja meg, akkor lát egy példát egy jól strukturált robot.txt fájlra.

A fájl egyszerű, de hatékony. Ez a példafájl nem tesz különbséget a robotok között. A parancsokat az összes robotnak a Felhasználói ügynök: * irányelv. Ez azt jelenti, hogy az azt követő összes parancs azokra a robotokra vonatkozik, amelyek a webhelyet felkeresik és feltérképezik.
A webrobotok meghatározása
Megadhat konkrét szabályokat aspeciális webrobotok. Megengedheti például, hogy a Googlebot (a Google internetes bejárója) feltérképezzék az összes cikkét a webhelyén, de érdemes lehet megakadályozni az Yandex Bot orosz internetes bejárót a webhelyén olyan cikkeket feltérképezni, amelyek oroszországi információt rontanak.
Több száz internetes bejáró használja az internetet a webhelyekkel kapcsolatos információk keresése céljából, de itt találja a 10 leggyakoribb, amelyet aggódnia kell.
- Googlebot: Google keresőmotor
- Bingbot: A Microsoft Bing keresőmotorja
- Slurp: Yahoo kereső
- DuckDuckBot: DuckDuckGo kereső
- Baiduspider: Kínai Baidu kereső
- YandexBot: Orosz Yandex kereső
- Exabot: Francia Exalead kereső
- Facebot: A Facebook feltérképező robotja
- ia_archiver: Alexa internetes rangsorolási robotja
- MJ12bot: Nagy hivatkozású indexelő adatbázis
Vegyük a fenti példahelyzetet, ha akarodahhoz, hogy a Googlebot mindent indexelhessen a webhelyén, de meg akarta akadályozni, hogy a Yandex az orosz alapú cikktartalmat indexelje, a következő sorokat kell hozzáadnia a robots.txt fájlhoz.
User-agent: googlebot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
User-agent: yandexbot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
Disallow: /russia/
Mint láthatja, az első szakasz csak blokkoljaA Google nem feltérképezi a WordPress bejelentkezési oldalát és az adminisztrációs oldalakat. A második szakasz blokkolja a Yandexet ugyanabból, hanem a webhelyének teljes területéből, ahol Oroszország-ellenes tartalommal rendelkező cikkeket tett közzé.
Ez egy egyszerű példa a tiltása parancs az Ön webhelyét látogató webrobotok irányítására.
Egyéb Robots.txt parancsok
A Disallow nem az egyetlen parancs, amelyhez hozzáférhetsz a robots.txt fájlban. Használhatja a többi parancsot is, amelyek irányítják, hogy egy robot miként mászhat be az Ön webhelyén.
- tiltása: Felszólítja a felhasználói ügynököt, hogy kerülje el a meghatározott URL-ek vagy a webhely teljes szakaszának feltérképezését.
- Lehetővé teszi: Lehetővé teszi a webhely meghatározott oldalainak vagy almappáinak finomítását, annak ellenére, hogy esetleg letiltotta a szülőmappát. Például letilthatja: / about /, de engedélyezheti: / about / ryan /.
- Crawl-delay: Ez arra szólítja fel a bejárót, hogy várjon xx másodpercig, mielőtt megkezdi a webhely tartalmának feltérképezését.
- Oldaltérkép: Adjon meg keresőmotoroknak (Google, Ask, Bing és Yahoo) az XML webhelytérképeinek helyét.
Ne feledje, hogy a botok fognak csak hallgassa meg a parancsokat, amelyeket megadott, amikor megadja a robot nevét.
Az emberek általánosan elkövetett hiba az, hogy tiltja az olyan területeket, mint a / wp-admin / az összes botból, de akkor adjon meg egy googlebot szakaszt, és csak más területeket (például / kb /) tiltjon le.
Mivel a botok csak a szakaszukban megadott parancsokat követik, meg kell újraismételnie azokat a többi parancsot, amelyeket az összes botra megadott (a * user-agent használatával).
- tiltása: A parancs arra szólítja fel a felhasználói ügynököt, hogy ne mutasson be egy adott URL-t. Minden URL-hez csak egy „Tiltás:” sor megengedett.
- Engedélyezés (csak a Googlebot esetében alkalmazható): A Googlebot parancsával hozzáférhet egy oldalhoz vagy almappához, még akkor is, ha a szülő oldalát vagy az almappáját letiltják.
- Crawl-delay: Hány másodpercig kell a robotnak várnia, mielőtt betölti és bejárja az oldal tartalmát. Vegye figyelembe, hogy a Googlebot nem ismeri el ezt a parancsot, de a bejárási sebesség beállítható a Google Search Console-ban.
- Oldaltérkép: Az URL-hez társított XML webhelytérkép (ek) helyének kihívására szolgál. Vegye figyelembe, hogy ezt a parancsot csak a Google, a Ask, a Bing és a Yahoo támogatja.
Ne feledje, hogy a robots.txt célja az, hogy a legális robotok (például a keresőmotorok robotjai) hatékonyabban feltérképezzék webhelyét.
Nagyon sok gonosz bejáró vanamelyek feltérképezik a webhelyét, hogy olyan dolgokat végezzen, mint például az e-mail címek lekaparása vagy a tartalom ellopása. Ha meg akarja próbálni a robots.txt fájlt, hogy megakadályozza a robotokat abban, hogy bármi feltérképezzenek a webhelyén, ne aggódjon. A bejárók készítői általában figyelmen kívül hagynak mindent, amit a robots.txt fájlba helyezett.
Miért tilthat bármit?
A legtöbb webhelytulajdonos elsődleges szempont, hogy a Google keresőmotorja minél több minőségi tartalmat mutasson be webhelyén.
A Google azonban csak korlátozott mértékben költ feltérképezési költségvetés és feltérképezési sebesség az egyes oldalakon. A feltérképezés aránya azt jelenti, hogy a Googlebot másodpercenként hány kérést fog tenni az Ön webhelyére a feltérképezési esemény során.
Ennél fontosabb a feltérképezési költségvetés, így vansok teljes kérelem, amelyet a Googlebot feltesz egy webhelyen való feltérképezésre. A Google „feltölti” feltérképezési költségvetését azáltal, hogy a webhely olyan területeire összpontosít, amelyek nagyon népszerűek vagy nemrégiben megváltoztak.
Nem vak vagy ezen információk iránt. Ha ellátogat a Google Webmestereszközökbe, láthatja, hogy a bejáró hogyan kezeli a webhelyet.

Mint láthatja, a bejáró minden nap állandóan tartja tevékenységét a webhelyén. Nem feltérképezi az összes webhelyet, hanem csak azokat, amelyeket a legfontosabbnak tartja.
Miért hagyja a Googlebot bírója eldönteni, hogy mi történikfontos webhelyén, amikor a robots.txt fájl segítségével megmondhatja, mi a legfontosabb oldal? Ez megakadályozza, hogy a Googlebot pazarolja az idejét webhelye alacsony értékű oldalain.
A feltérképezési költségkeret optimalizálása
A Google Webmester Eszközök segítségével ellenőrizheti, hogy a Googlebot olvassa-e a robots.txt fájlt, és vannak-e hibák.
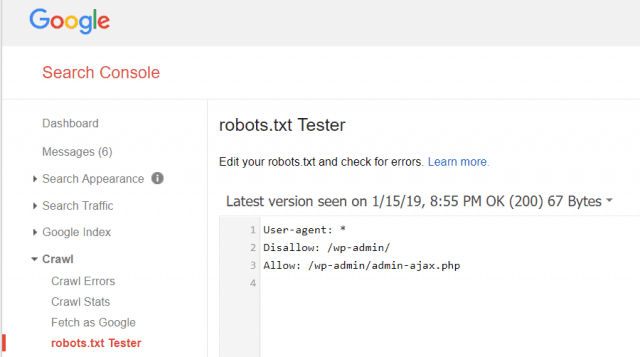
Ez segít ellenőrizni, hogy a robots.txt fájlt megfelelően szerkesztette-e.
Milyen oldalakat kellene tiltania a Googlebotról? Jó, ha webhelyének SEO nem engedélyezi az alábbi kategóriák használatát.
- Másolatos oldalak (például nyomtatóbarát oldalak)
- Köszönjük az űrlap alapú megrendeléseket követő oldalakat
- Megrendelés vagy információ lekérdezési űrlapok
- Kapcsolattartási oldalak
- Bejelentkezés oldal
- Ólommágneses „értékesítési” oldalak
Ne hagyja figyelmen kívül a Robots.txt fájlt
Az új webhelyek tulajdonosai által a legnagyobb hiba azmég a robots.txt fájlt sem nézi meg. A legrosszabb helyzet az lehet, hogy a robots.txt fájl valójában megakadályozza az Ön webhelyét vagy annak egy részét, hogy egyáltalán ne mászjon be.
Feltétlenül ellenőrizze a robots.txt fájlt és ellenőrizze annak optimalizálását. Ily módon a Google és más fontos keresőmotorok „látják” az összes fantasztikus dolgot, amelyet webhelyén kínál a világ számára.
![Csatlakozzon az Active Directory Windows tartományához a Windows 7 vagy a Vista operációs rendszerrel [Útmutató]](/images/vista/join-an-active-directory-windows-domain-with-windows-7-or-vista-how-to.png)









Szólj hozzá