Що таке файл Robots.txt у домені?

Однією з найбільших помилок для власників нових веб-сайтів є не дивлячись на файл robots.txt. То що це все-таки і чому так важливо? У нас є ваші відповіді.
Якщо ви володієте веб-сайтом і дбаєте про йогоSEO здоров’я, ви повинні ознайомитись із файлом robots.txt у вашому домені. Вірите чи ні, це надзвичайно велика кількість людей, які швидко запускають домен, встановлюють швидкий веб-сайт WordPress і ніколи не заважають робити щось зі своїм файлом robots.txt.
Це небезпечно. Неправильно налаштований файл robots.txt може насправді зруйнувати SEO-здоров’я вашого веб-сайту та пошкодити будь-які шанси на збільшення вашого трафіку.
Що таке файл Robots.txt?
The Robots.txt файл влучно названий, тому що він по суті єфайл, у якому перераховані директиви веб-роботів (як роботів пошукової системи) про те, як і що вони можуть сканувати на вашому веб-сайті. Це веб-стандарт, за яким слід веб-сайти з 1994 року, і всі основні веб-сканери дотримуються цього стандарту.
Файл зберігається у текстовому форматі (з a.розширення txt) у кореневій папці вашого веб-сайту. Насправді ви можете переглянути файл robot.txt будь-якого веб-сайту, просто ввівши домен, а потім /robots.txt. Якщо ви спробуєте це з groovyPost, ви побачите приклад добре структурованого файлу robot.txt.

Файл простий, але ефективний. Цей приклад не відрізняє роботів. Команди видаються всім роботам за допомогою Користувач-агент: * директива. Це означає, що всі команди, які слідують за ним, стосуються всіх роботів, які відвідують сайт, щоб сканувати його.
Вказання веб-сканерів
Ви також можете вказати конкретні правила дляконкретні веб-сканери. Наприклад, ви можете дозволити Googlebot (веб-сканеру Google) сканувати всі статті на вашому веб-сайті, але ви можете заборонити російському веб-сканеру Yandex Bot від сканування статей на вашому сайті, які мають зневажливу інформацію про Росію.
Є сотні веб-сканерів, які шукають в Інтернеті інформацію про веб-сайти, але тут перелічено 10 найпоширеніших, про які ви повинні турбуватися.
- Googlebot: Пошукова система Google
- Бінгбот: Пошукова система Microsoft Bing
- Сірка: Пошукова система Yahoo
- DuckDuckBot: Пошукова система DuckDuckGo
- Байдуспідер: Китайська пошукова система Baidu
- Яндекс.Бот: Російська пошукова система Яндекс
- Екзабот: Французька пошукова система Exalead
- Facebot: Повний бот у Facebook
- ia_archiver: Гусеничний веб-рейтинг Alexa
- MJ12bot: Велика база даних індексації посилань
Беручи приклад вищезгаданого сценарію, якщо хочетещоб дозволити Googlebot індексувати все на вашому веб-сайті, але хочете заблокувати Yandex не індексувати вміст статті на російській основі, ви додасте наступні рядки до файлу robots.txt.
User-agent: googlebot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
User-agent: yandexbot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
Disallow: /russia/
Як бачимо, перший розділ лише блокуєGoogle сканує вашу сторінку входу в WordPress та адміністративні сторінки. Другий розділ блокує Яндекс з того самого, але також і з усієї області вашого сайту, де ви публікували статті з антиросійським вмістом.
Це простий приклад того, як можна використовувати Заборонити команда для управління певними веб-сканерами, які відвідують ваш веб-сайт.
Інші команди Robots.txt
Disallow - не єдина команда, до якої ви маєте доступ у своєму файлі robots.txt. Ви також можете використовувати будь-які інші команди, які спрямовуватимуть, як робот може сканувати ваш сайт.
- Заборонити: Повідомляє користувальницький агент, щоб уникнути сканування конкретних URL-адрес або цілих розділів вашого сайту.
- Дозволити: Дозволяє точно налаштовувати певні сторінки або підпапки на вашому сайті, навіть якщо ви, можливо, заборонили батьківську папку. Наприклад, ви можете заборонити: / about /, але тоді дозволити: / about / ryan /.
- Сканування-затримка: Це скаже сканеру почекати xx кількість секунд, перш ніж почати сканувати вміст сайту.
- Карта сайту: Надайте пошуковим системам (Google, Ask, Bing та Yahoo) розташування ваших XML-мап.
Майте на увазі, що боти будуть тільки слухайте команди, які ви надали, коли вказуєте ім’я бота.
Поширеною помилкою, яку люди роблять, є заборона таких областей, як / wp-admin /, від усіх ботів, але потім вказати розділ googlebot і забороняти лише інші області (наприклад, / про /).
Оскільки боти виконують лише команди, вказані в їх розділі, вам потрібно перезапустити всі ті інші команди, які ви вказали для всіх ботів (використовуючи * user-agent).
- Заборонити: Команда, що використовується для того, щоб сказати користувачеві-агенту не сканувати конкретний URL. Для кожної URL-адреси дозволений лише один рядок "Заборонити:".
- Дозволити (застосовується лише для Googlebot): Команда сказати Googlebot, що він може отримати доступ до сторінки або підпапки, навіть якщо його батьківська сторінка або підпапка можуть бути заборонені.
- Сканування-затримка: Скільки секунд сканер повинен чекати, перш ніж завантажувати та сканувати вміст сторінки. Зауважте, що Googlebot не підтверджує цю команду, але швидкість сканування можна встановити в Пошуковій консолі Google.
- Карта сайту: Використовується для виклику місця розташування карти XML, пов’язаних з цією URL-адресою. Зверніть увагу, що ця команда підтримується лише Google, Ask, Bing та Yahoo.
Майте на увазі, що robots.txt покликаний допомогти законним ботам (наприклад, ботам пошукових систем) ефективніше сканувати ваш сайт.
Там дуже багато підступних гусеницьякі сканують ваш сайт, щоб робити такі речі, як скребки електронних адрес або викрадати ваш вміст. Якщо ви хочете спробувати використати файл robots.txt, щоб заблокувати ці сканери не сканувати щось на вашому сайті, не турбуйтеся. Творці цих сканерів зазвичай ігнорують все, що ви додали у свій файл robots.txt.
Чому забороняти щось?
Здійснення пошуку пошукової системи Google для сканування якомога більше якісного вмісту на вашому веб-сайті є основною проблемою для більшості власників веб-сайтів.
Однак Google витрачає лише обмежені сканувати бюджет і швидкість сканування на окремих сайтах. Коефіцієнт сканування - це кількість запитів на секунду, які Googlebot зробить на ваш сайт під час події сканування.
Більш важливим є бюджет сканування, саме такбагато робочих запитів Googlebot зробить сканування вашого сайту за один сеанс. Google "витрачає" бюджет на сканування, орієнтуючись на області вашого веб-сайту, які дуже популярні або останнім часом змінилися.
Ви не сліпі до цієї інформації. Якщо ви відвідаєте Інструменти Google для веб-майстрів, ви зможете побачити, як сканер обробляє ваш сайт.

Як бачите, сканер постійно щодня підтримує активність на вашому сайті. Він сканує не всі сайти, а лише ті, які він вважає найважливішими.
Навіщо залишати це Googlebot, щоб вирішити, що робитиважливо на вашому сайті, коли ви можете використовувати свій файл robots.txt, щоб розповісти, які найбільш важливі сторінки? Це не дасть Googlebot витрачати час на низькоцінних сторінках вашого сайту.
Оптимізація бюджету сканування
Інструменти Google для веб-майстрів також дозволяють вам перевірити, чи Googlebot добре читає ваш файл robots.txt та чи є помилки.
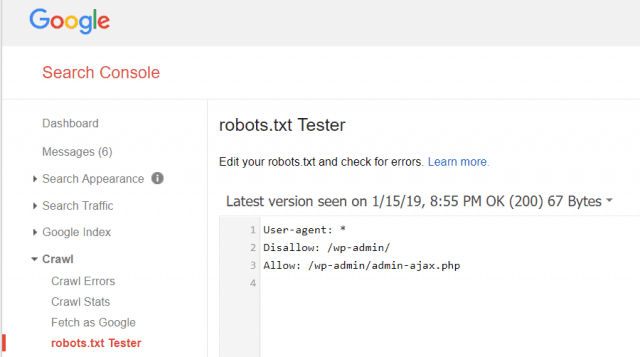
Це допоможе вам перевірити, чи правильно ви структурували файл robots.txt.
Які сторінки слід заборонити від Googlebot? Добре для SEO вашого сайту забороняти забороняти використання таких категорій сторінок.
- Скопійовані сторінки (наприклад, друковані сторінки)
- Дякуємо сторінкам, що виконують замовлення на основі форми
- Бланки запитів чи інформації
- Контактні сторінки
- Сторінки для входу
- Сторінки «продажу» провідного магніту
Не ігноруйте файл Robots.txt
Найбільша помилка нових власників веб-сайтів - ценіколи навіть не дивлячись на їх файл robots.txt. Найгірша ситуація може полягати в тому, що файл robots.txt насправді блокує сканування вашого сайту або районів вашого сайту.
Переконайтесь, що перегляньте файл robots.txt і переконайтеся, що він оптимізований. Таким чином, Google та інші важливі пошукові системи "бачать" всі чудові речі, які ви пропонуєте світові на своєму веб-сайті.
![Приєднайтеся до домену Windows Active Directory з Windows 7 або Vista [How to To]](/images/vista/join-an-active-directory-windows-domain-with-windows-7-or-vista-how-to.png)









Залишити коментар