Ce este fișierul Robots.txt într-un domeniu?

Una dintre cele mai mari greșeli ale noilor proprietari de site-uri web este să nu se uite în fișierul lor robots.txt. Deci, ce este oricum și de ce atât de important? Avem răspunsurile tale.
Dacă dețineți un site web și vă pasă de site-ul dvs.Sănătate SEO, ar trebui să vă familiarizați cu fișierul robots.txt din domeniul dvs. Credeți sau nu, este un număr perturbator de mare de oameni care lansează rapid un domeniu, instalează un site WordPress rapid și nu vă deranjați să faceți nimic cu fișierul lor robots.txt.
Asta e periculos. Un fișier robots.txt prost configurat poate distruge sănătatea SEO a site-ului dvs. și poate deteriora toate șansele pe care le aveți pentru creșterea traficului.
Ce este fișierul Robots.txt?
În Robots.txt fișierul este numit în mod adecvat, deoarece este în esență unfișier care listează directivele pentru roboții web (cum ar fi roboții motoarelor de căutare) despre cum și ce pot să se târască pe site-ul dvs. web. Acesta a fost un standard web urmat de site-uri web din 1994 și toate crawler-urile majore respectă standardul.
Fișierul este stocat în format text (cu un.extensie txt) din folderul rădăcină al site-ului dvs. De fapt, puteți vizualiza orice fișier robot.txt al site-ului web doar tastând domeniul urmat de /robots.txt. Dacă încercați acest lucru cu groovyPost, veți vedea un exemplu de fișier robot.txt bine structurat.

Fișierul este simplu, dar eficient. Acest fișier de exemplu nu diferențiază între roboți. Comenzile sunt emise tuturor roboților folosind butonul Agent utilizator: * directivă. Aceasta înseamnă că toate comenzile care îl urmează se aplică tuturor roboților care vizitează site-ul pentru a-l accesa.
Specificarea crawlerilor web
De asemenea, puteți specifica reguli specifice pentrucrawlere web specifice. De exemplu, ați putea permite Googlebot (crawler-ul web Google) să ruleze toate articolele de pe site-ul dvs., dar este posibil să doriți să nu permiteți crawler-ului rusesc Yandex Bot să se articole pe site-ul dvs. care să aibă informații disprețuitoare despre Rusia.
Există sute de crawlere web care parcurg internetul pentru informații despre site-uri web, dar cele mai frecvente 10 de care ar trebui să vă preocupați sunt enumerate aici.
- Googlebot: Motorul de căutare Google
- Bingbot: Motorul de căutare Bing al Microsoft
- Slurp: Motorul de căutare Yahoo
- DuckDuckBot: Motorul de căutare DuckDuckGo
- Baiduspider: Motorul de căutare chinezesc Baidu
- YandexBot: Motorul de căutare Yandex rus
- Exabot: Motor de căutare francez Exalead
- Facebot: Botul cu crawlere Facebook
- ia_archiver: Crawlerul de rang web al Alexa
- MJ12bot: Baza de date de indexare a legăturilor mari
Luând exemplul de mai sus, dacă vreipentru a permite Googlebot să indice totul de pe site-ul dvs., dar a vrut să împiedice Yandex să indexeze conținutul articolului dvs. rus, veți adăuga următoarele linii în fișierul dvs. robots.txt.
User-agent: googlebot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
User-agent: yandexbot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
Disallow: /russia/
După cum puteți vedea, prima secțiune se blochează doarGoogle de la crawling pagina dvs. de conectare WordPress și paginile administrative. A doua secțiune blochează Yandex din același, dar și din întreaga zonă a site-ului dvs. în care ați publicat articole cu conținut anti-Rusia.
Acesta este un exemplu simplu al modului în care puteți utiliza funcția Disallow comanda de a controla anumite crawlere web care vă vizitează site-ul.
Alte comenzi Robots.txt
Interzicerea nu este singura comandă la care aveți acces în fișierul dvs. robots.txt. Puteți utiliza, de asemenea, oricare dintre celelalte comenzi care vă vor direcționa modul în care un robot vă poate accesa site-ul.
- Disallow: Anunță agentul utilizator să evite să se târască URL-uri specifice sau secțiuni întregi ale site-ului dvs.
- Permite: Vă permite să reglați anumite pagini sau subfoldere de pe site-ul dvs., chiar dacă ați putea renunța la un folder părinte. De exemplu, puteți dezactiva: / despre /, dar apoi permiteți / / despre / ryan /.
- Crawl de întârziere: Acest lucru îi spune crawlerului să aștepte xx numărul de secunde înainte de a începe să parcurgă conținutul site-ului.
- Harta site-ului: Furnizați motoarelor de căutare (Google, Ask, Bing și Yahoo) locația site-urilor dvs. XML.
Rețineți că roboții vor numai ascultați comenzile pe care le-ați furnizat atunci când specificați numele botului.
O greșeală obișnuită pe care o fac oamenii este de a refuza zonele precum / wp-admin / de la toate roboții, dar apoi specificați o secțiune googlebot și nu permiteți decât alte zone (cum ar fi / despre /).
Întrucât roboții nu urmăresc decât comenzile specificate în secțiunea lor, trebuie să restabiliți toate celelalte comenzi pe care le-ați specificat pentru toți roboții (folosind * user-agent).
- Disallow: Comanda folosită pentru a spune unui agent utilizator să nu cearcănească o anumită adresă URL. Pentru fiecare adresă URL este permisă doar o singură linie „Renunță:”.
- Permite (se aplică numai pentru Googlebot): Comanda de a-i spune Googlebot că poate accesa o pagină sau subfolder, chiar dacă pagina sau subfolderul parental poate fi respins.
- Crawl de întârziere: Câte secunde ar trebui să aștepte un crawler înainte de a încărca și a accesa conținutul paginii. Rețineți că Googlebot nu recunoaște această comandă, dar rata de accesare a crawlului poate fi setată în Google Search Console.
- Harta site-ului: Folosit pentru apelarea locației unui sitemap XML asociat cu această adresă URL. Rețineți că această comandă este acceptată doar de Google, Ask, Bing și Yahoo.
Rețineți că robots.txt are rolul de a ajuta roboții legitimați (cum ar fi robotii de căutare) să-și acceseze mai eficient site-ul.
Există o mulțime de crawlere nefaste acolocare te târăsc pe site-ul tău pentru a face lucruri precum razuirea adreselor de e-mail sau pentru a-ți fura conținutul. Dacă doriți să încercați să folosiți fișierul dvs. robots.txt pentru a bloca acei crawlere să nu acceseze nimic pe site-ul dvs., nu vă deranjați. Creatorii acelor crawlere ignoră, de obicei, tot ceea ce ați introdus în fișierul dvs. robots.txt.
De ce să respingi ceva?
Obținerea motorului de căutare Google pentru a trage cât mai mult conținut de calitate pe site-ul dvs. este o preocupare principală pentru majoritatea proprietarilor de site-uri web.
Cu toate acestea, Google cheltuiește doar un număr limitat buget crawl și rata de rasturnare pe site-uri individuale. Rata de accesare la crawlere este numărul de solicitări pe secundă pe Googlebot pe site-ul dvs. în timpul evenimentului de crawling.
Mai important este bugetul de accesare, care este modulmulte solicitări totale pe care Googlebot le va face pentru a-ți trage site-ul într-o singură sesiune. Google își „cheltuiește” bugetul de accesare cu crawlere concentrându-se pe zonele site-ului dvs. care sunt foarte populare sau s-au schimbat recent.
Nu sunteți orbi de aceste informații. Dacă accesați Instrumentele Google Webmaster, puteți vedea modul în care crawlerul vă gestionează site-ul.

După cum vedeți, crawlerul își menține activitatea pe site-ul dvs. destul de constant în fiecare zi. Nu parcurge toate site-urile, ci doar cele pe care le consideră cele mai importante.
De ce lăsați la Googlebot să decidă ce esteimportant pe site-ul dvs., când puteți utiliza fișierul dvs. robots.txt pentru a-i spune care sunt cele mai importante pagini? Acest lucru va împiedica Googlebot să piardă timpul în paginile cu valoare scăzută de pe site-ul dvs.
Optimizarea bugetului dvs. de accesare
Instrumentele pentru webmaster Google vă permite, de asemenea, să verificați dacă Googlebot citește fișierul dvs. robots.txt bine și dacă există erori.
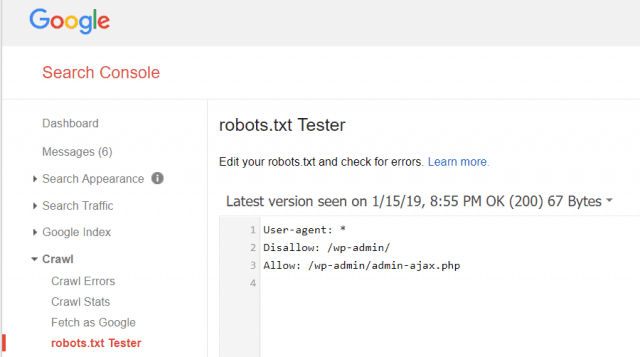
Acest lucru vă ajută să verificați dacă ați structurat corect fișierul dvs. robots.txt.
Ce pagini ar trebui să renunțați la Googlebot? Este bine ca site-ul dvs. SEO să nu permită următoarele categorii de pagini.
- Pagini duplicate (cum ar fi pagini prietenoase cu imprimanta)
- Vă mulțumim pagini în urma comenzilor bazate pe formular
- Formulare de interogare pentru comenzi sau informații
- Pagini de contact
- Pagini de conectare
- Pagini „vânzări” ale magnetului de plumb
Nu ignorați fișierul dvs. Robots.txt
Cea mai mare greșeală pe care o fac noi proprietarii de site-uri web esteniciodată nu se uită la fișierul lor robots.txt. Cea mai gravă situație ar putea fi că fișierul robots.txt blochează de fapt site-ul dvs. sau zonele site-ului dvs., de la a nu fi accesate cu crawlere.
Asigurați-vă că consultați fișierul dvs. robots.txt și asigurați-vă că este optimizat. Astfel, Google și alte motoare de căutare importante „văd” toate lucrurile fabuloase pe care le oferiți lumii cu site-ul dvs. web.
![Alăturați-vă unui domeniu Windows Active Directory cu Windows 7 sau Vista [Cum să faceți]](/images/vista/join-an-active-directory-windows-domain-with-windows-7-or-vista-how-to.png)









Lasa un comentariu