Hva er Robots.txt-filen i et domene?

En av de største feilene for nye nettstedseiere er ikke å se på robots.txt-filen deres. Så hva er det likevel, og hvorfor så viktig? Vi har svarene dine.
Hvis du eier et nettsted og bryr deg om nettstedet dittSEO helse, bør du gjøre deg veldig kjent med robots.txt-filen på domenet ditt. Tro det eller ei, det er et urovekkende høyt antall mennesker som raskt lanserer et domene, installerer et raskt WordPress-nettsted og aldri gidder å gjøre noe med robots.txt-filen.
Dette er farlig. En dårlig konfigurert robots.txt-fil kan faktisk ødelegge nettstedets SEO-helse, og skade sjansene du måtte ha for å øke trafikken.
Hva er Robots.txt-filen?
De Robots.txt filen er passende navngitt fordi den egentlig er enfil som viser direktiver for nettroboter (som søkemotoroboter) om hvordan og hva de kan gjennomsøke på nettstedet ditt. Dette har vært en nettstandard fulgt av nettsteder siden 1994, og alle større webcrawlere overholder standarden.
Filen lagres i tekstformat (med en.txt-utvidelse) på rotmappen til nettstedet ditt. Du kan faktisk se robot.txt-filen til ethvert nettsted bare ved å skrive inn domenet etterfulgt av /robots.txt. Hvis du prøver dette med groovyPost, ser du et eksempel på en godt strukturert robot.txt-fil.

Filen er enkel, men effektiv. Denne eksempelfilen skiller ikke mellom roboter. Kommandoene blir gitt til alle roboter ved å bruke Bruker agent: * direktiv. Dette betyr at alle kommandoer som følger den, gjelder alle roboter som besøker nettstedet for å gjennomsøke det.
Spesifisering av nettlesere
Du kan også spesifisere spesifikke regler forspesifikke webcrawlers. Du kan for eksempel la Googlebot (Googles webcrawler) gjennomgå alle artiklene på nettstedet ditt, men det kan være lurt å avvise den russiske nettcrawleren Yandex Bot fra å gjennomsøke artikler på nettstedet ditt som har nedslående informasjon om Russland.
Det er hundrevis av webcrawlers som søker på internett for informasjon om nettsteder, men de 10 vanligste du bør være opptatt av er listet opp her.
- Googlebot: Googles søkemotor
- Bingbot: Microsofts Bing-søkemotor
- slurp: Yahoo-søkemotoren
- DuckDuckBot: DuckDuckGo søkemotor
- Baiduspider: Kinesisk Baidu-søkemotor
- YandexBot: Russisk Yandex søkemotor
- Exabot: Fransk Exalead søkemotor
- Facebot: Facebooks gjennomsøkende bot
- ia_archiver: Alexa's crawler på nettet
- MJ12bot: Indekseringsdatabase med stor lenke
Ta eksempelet ovenfor, hvis du vilfor å tillate Googlebot å indeksere alt på nettstedet ditt, men ønsket å blokkere Yandex fra å indeksere russiskbasert artikkelinnhold, ville du legge til følgende linjer i robots.txt-filen.
User-agent: googlebot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
User-agent: yandexbot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
Disallow: /russia/
Som du ser blokkerer den første delen bareGoogle fra å gjennomsøke innloggingssiden og WordPress-siden for WordPress. Den andre delen blokkerer Yandex fra det samme, men også fra hele området på nettstedet ditt der du har publisert artikler med anti-Russland-innhold.
Dette er et enkelt eksempel på hvordan du kan bruke Disallow kommando for å kontrollere spesifikke webcrawlers som besøker nettstedet ditt.
Andre Robots.txt-kommandoer
Disallow er ikke den eneste kommandoen du har tilgang til i robots.txt-filen. Du kan også bruke hvilken som helst av de andre kommandoene som vil lede hvordan en robot kan gjennomsøke nettstedet ditt.
- Disallow: Ber brukeragenten for å unngå å gjennomsøke spesifikke nettadresser, eller hele deler av nettstedet ditt.
- Tillate: Lar deg finjustere bestemte sider eller undermapper på nettstedet ditt, selv om du kanskje har avvist en overordnet mappe. For eksempel kan du ikke tillate: / om /, men deretter tillate: / om / ryan /.
- Crawl-forsinkelse: Dette forteller crawleren om å vente xx antall sekunder før han begynner å gjennomsøke innholdet på nettstedet.
- sitemap: Gi søkemotorer (Google, Ask, Bing og Yahoo) plasseringen av XML-nettkartene.
Husk at roboter vil gjøre det kun lytte til kommandoene du har gitt når du spesifiserer navnet på bot.
En vanlig feil folk gjør er å ikke tillate områder som / wp-admin / fra alle boter, men spesifiser deretter en googlebot-seksjon og bare tillater andre områder (som / om /).
Siden bots bare følger kommandoene du spesifiserer i seksjonen, må du endre om på alle de andre kommandoene du har spesifisert for alle boter (ved å bruke * brukeragenten).
- Disallow: Kommandoen brukes til å fortelle en brukeragent om ikke å gjennomsøke en bestemt URL. Bare en "Disallow:" -linje er tillatt for hver URL.
- Tillat (gjelder bare for Googlebot): Kommandoen for å fortelle Googlebot at den kan få tilgang til en side eller undermappe selv om dens forside eller undermappe kan ikke tillates.
- Crawl-forsinkelse: Hvor mange sekunder en gjennomsøker skal vente før side lastes inn og gjennomsøkes. Merk at Googlebot ikke anerkjenner denne kommandoen, men gjennomsøkingsfrekvens kan angis i Google Search Console.
- Sitemap: Brukes til å ringe ut plasseringen til et XML-sitemap (er) tilknyttet denne URL-en. Merk at denne kommandoen bare støttes av Google, Ask, Bing og Yahoo.
Husk at robots.txt er ment å hjelpe legitime roboter (som søkemotorbots) til å gjennomsøke nettstedet ditt mer effektivt.
Det er mange ubehagelige gjennomsøkere der utesom gjennomsøker nettstedet for å gjøre ting som å skrape e-postadresser eller stjele innholdet ditt. Hvis du vil prøve å bruke robots.txt-filen din til å blokkere crawlerne fra å gjennomsøke noe på nettstedet ditt, må du ikke bry deg. Skaperne av disse gjennomsøkere ignorerer vanligvis alt du har lagt inn i robots.txt-filen.
Hvorfor ikke tillate noe?
Å få Googles søkemotor til å gjennomsøke så mye kvalitetsinnhold på nettstedet ditt som mulig, er et hovedanliggende for de fleste nettstedseiere.
Imidlertid bruker Google bare et begrenset gjennomgå budsjett og gjennomsøkingsfrekvens på individuelle nettsteder. Gjennomsøkingsfrekvensen er hvor mange forespørsler per sekund Googlebot kommer til nettstedet ditt under gjennomsøkingshendelsen.
Viktigere er gjennomsøkingsbudsjettet, som er hvordanmange totale forespørsler Googlebot vil komme til å gjennomsøke nettstedet ditt i en økt. Google "bruker" gjennomsøkingsbudsjettet ved å fokusere på områder på nettstedet ditt som er veldig populære eller har endret seg i det siste.
Du er ikke blind for denne informasjonen. Hvis du besøker Googles verktøy for nettredaktører, kan du se hvordan søkeroboten håndterer nettstedet ditt.

Som du kan se, holder søkeroboten sin aktivitet på nettstedet ditt ganske konstant hver dag. Den gjennomsøker ikke alle nettsteder, men bare de den anser som de viktigste.
Hvorfor overlate det til Googlebot å bestemme hva som skjerviktig på nettstedet ditt, når du kan bruke robots.txt-filen til å fortelle den hva de viktigste sidene er? Dette vil forhindre Googlebot i å kaste bort tid på sider med lav verdi på nettstedet ditt.
Optimaliser gjennomsøkingsbudsjettet
Google Webmaster Tools lar deg også sjekke om Googlebot leser robots.txt-filen din bra, og om det er feil.
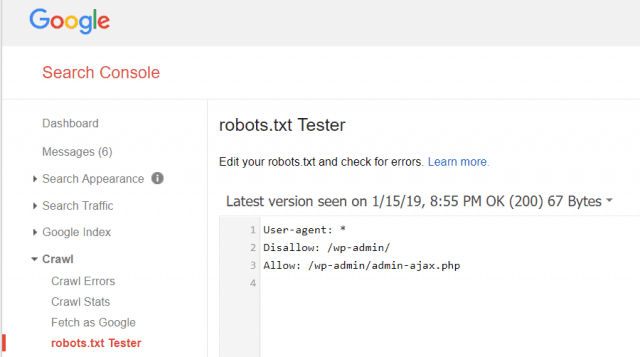
Dette hjelper deg med å bekrefte at du har strukturert robots.txt-filen riktig.
Hvilke sider bør du ikke tillate fra Googlebot? Det er bra for SEO-nettstedet ditt å ikke tillate følgende sidekategorier.
- Dupliserte sider (som utskriftsvennlige sider)
- Takk sider etter skjemabaserte ordrer
- Bestillings- eller informasjonsspørreskjemaer
- Kontaktsider
- Påloggingssider
- Lead magnet "salg" sider
Ignorer ikke Robots.txt-filen
Den største feilen nye eiere av nettstedet gjør eraldri en gang å se på robots.txt-filen deres. Den verste situasjonen kan være at robots.txt-filen faktisk blokkerer nettstedet ditt, eller områder på nettstedet ditt, i å bli gjennomgått i det hele tatt.
Sørg for å gå gjennom robots.txt-filen din, og sørg for at den er optimalisert. På denne måten "ser" Google og andre viktige søkemotorer alle de fantastiske tingene du tilbyr verden med nettstedet ditt.
![Bli med i et Active Directory Windows-domene med Windows 7 eller Vista [Slik gjør du det]](/images/vista/join-an-active-directory-windows-domain-with-windows-7-or-vista-how-to.png)









Legg igjen en kommentar