Шта је датотека Роботс.ткт у домени?

Једна од највећих грешака за нове власнике веб локација није гледање у њихову датотеку роботс.ткт. Па шта је то, и зашто је тако важно? Имамо ваше одговоре.
Ако имате веб локацију и бринете се о сајтуСЕО здравље, требало би да се веома добро упознате са датотеком роботс.ткт на вашем домену. Вјеровали или не, то је узнемирујуће велик број људи који брзо покрену домен, инсталирају брзу ВордПресс веб страницу и никада се не труде да раде било шта са својом роботс.ткт датотеком.
Ово је опасно. Лоше конфигурисана датотека роботс.ткт може заправо уништити СЕО здравље вашег веб локације и оштетити све шансе које имате за раст вашег промета.
Шта је датотека Роботс.ткт?
Тхе Robots.txt датотека је прикладно именована, јер је у основи адатотека која наводи директиве за веб роботе (попут робота претраживача) о томе како и шта могу индексирати на вашој веб локацији. Ово је веб стандард који следе веб локације од 1994. године и сви главни претраживачи се придржавају стандарда.
Датотека се чува у текстуалном формату (са.ткт екстензија) у коријенској мапи вашег вебсајта. У ствари, можете да видите датотеку робот.ткт било које веб локације само укуцавањем домена, а затим /роботс.ткт. Ако ово покушате са гроовиПост, видећете пример добро структуриране датотеке робот.ткт.

Датотека је једноставна, али ефикасна. Овај пример датотеке не разликује роботе. Команде се издају свим роботима коришћењем Кориснички агент: * директива. То значи да се све наредбе које га прате примењују на све роботе који посећују локацију како би је претражили.
Одређивање Веб претраживача
Можете такође да одредите одређена правила заодређени веб претраживачи. На пример, можете да омогућите Гооглеботу (Гоогле-овом претраживачу веб података) да претражи све чланке на вашој веб локацији, али можда желите да онемогућите руском претраживачу веб претраживача Иандек Бот да претражује чланке на вашој веб локацији који имају омаловажавајуће информације о Русији.
Постоји стотине веб претраживача који претражују интернет информацијама о веб локацијама, али овде је наведено 10 најчешћих због којих бисте требали бити забринути.
- Гооглебот: Гоогле претраживач
- Бингбот: Мицрософтов претраживач Бинг
- Сркати: Иахоо претраживач
- ДуцкДуцкБот: ДуцкДуцкГо претраживач
- Баидуспидер: Кинески претраживач Баиду
- ИандекБот: Руски претраживач Иандек
- Екабот: Француски претраживач Екалеад
- Фацебот: Фацебоок-ов ботац који се увуче
- иа_арцхивер: Алекса'с веб претраживач
- МЈ12бот: Велика база података за индексирање веза
Узимајући горњи пример примера, ако желитеда бисте дозволили Гооглеботу да индексира све на вашој веб локацији, али желео је да блокира Иандек да индексира ваш чланак на руском језику, додајте следеће редове у датотеку роботс.ткт.
User-agent: googlebot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
User-agent: yandexbot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
Disallow: /russia/
Као што видите, први одељак блокираГоогле са индексирања странице за пријаву на ВордПресс и административних страница. Други одељак блокира Иандек из истог, али и са целог подручја ваше веб локације у коме сте објавили чланке са анти-руским садржајем.
Ово је једноставан пример како можете да користите Онемогући наредба за контролу одређених веб претраживача који посећују вашу веб локацију.
Остале команде Роботс.ткт
Дисаллов није једина наредба којој имате приступ у датотеци роботс.ткт. Такође можете да користите било коју другу команду која ће усмеравати како робот може да претражи вашу веб локацију.
- Онемогући: Каже корисничком агенту да избегава индексирање одређених УРЛ-ова или целих секција ваше веб локације.
- Дозволи: Омогућује вам прецизно подешавање одређених страница или подмапа на вашој веб локацији, иако сте можда дозволили родитељску фасциклу. На пример, можете онемогућити: / абоут /, али дозволити: / абоут / риан /.
- Одлагање-одлагање: Ово поручује алата за претрагу да сачека кк број секунди пре него што почне да индексира садржај веб локације.
- Ситемап: Наведите претраживачима (Гоогле, Питај, Бинг и Иахоо) локацију ваших КСМЛ ситемапова.
Имајте на уму да ботови хоће само слушајте команде које сте унели када наведете име робота.
Честа грешка коју људи чине је онемогућавање подручја као што је / вп-админ / из свих ботова, али затим одредите одјељак гооглебот и само забрану осталих подручја (попут / абоут /).
Будући да ботови следе само наредбе које сте навели у њиховом одељку, морате поново да покренете све оне наредбе које сте навели за све ботове (користећи * усер-агент).
- Онемогући: Наредба која се користи да кажем корисничком агенту да не претражи индексирање одређеног УРЛ-а. За сваки УРЛ је дозвољен само један ред "Дисаллов:".
- Дозволи (важи само за Гооглебот): Наредба да се Гооглеботу каже да може приступити страници или поддиректоријуму иако његова матична страница или поддиректоријум могу бити онемогућени.
- Одлагање-одлагање: Колико секунди би алат за индексирање требало да сачека пре учитавања и претраживања садржаја странице. Имајте на уму да Гооглебот не признаје ову наредбу, али стопа претраживања може се поставити у Гоогле Сеарцх Цонсоле.
- Ситемап: Користи се за позивање локације КСМЛ ситемапа повезаних са овом УРЛ адресом. Имајте на уму да ову наредбу подржавају само Гоогле, Аск, Бинг и Иахоо.
Имајте на уму да је циљ роботс.ткт да помогне легитимним ботовима (попут ботова претраживача) да ефикасније прегледају вашу веб локацију.
Тамо има пуно гадних гусјеницакоји претражују вашу веб локацију да би радили ствари попут брисања адреса е-поште или украли ваш садржај. Ако желите да испробате и користите датотеку роботс.ткт да блокирате ове алате да не претражују било шта на вашој веб локацији, немојте се мучити. Креатори тих претраживача обично игноришу све што сте ставили у датотеку роботс.ткт.
Зашто забранити било шта?
Налажење Гоогле-овог претраживача да претражи што је могуће квалитетнији садржај на вашој веб локацији је главна брига за већину власника веб локација.
Међутим, Гоогле троши само ограничено претраживање буџета и стопа индексирања на појединачним локацијама. Стопа индексирања износи колико ће захтјева у секунди Гооглебот поднијети вашој веб локацији током догађаја претраживања.
Важнији је буџет за индексирање, а то је какомного укупних захтева које ће Гооглебот поднети да претражи вашу веб страницу у једној сесији. Гоогле „троши“ буџет за индексирање фокусирајући се на области ваше веб странице које су веома популарне или су се недавно промениле.
Ниси слеп за ове информације. Ако посетите Гоогле алатке за вебмастере, можете видети како алат за индексирање обрађује вашу веб локацију.

Као што видите, алат за индексирање свакодневно одржава активност на вашој веб локацији. Не претражују се све веб локације, већ само оне које сматра најважнијим.
Зашто то остављате Гооглебот-у да одлучи шта јеВажно је на вашој веб локацији када помоћу датотеке роботс.ткт можете да јој кажете које су најважније странице? То ће спречити Гооглебот да троши вријеме на страницама мале вриједности на вашој веб локацији.
Оптимизирање буџета за индексирање
Гоогле алати за вебмастере такође вам омогућавају да проверите да ли Гооглебот добро чита вашу датотеку роботс.ткт и да ли постоје грешке.
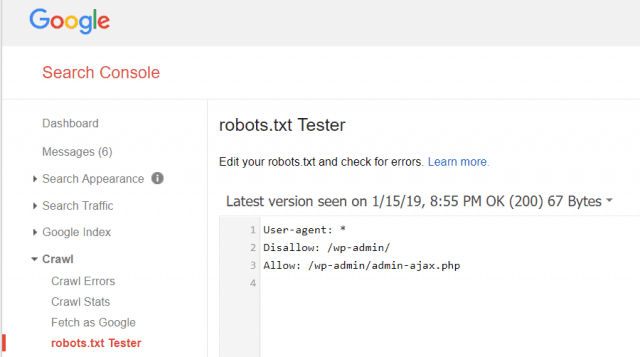
Ово вам помаже да проверите да ли сте правилно структурирали датотеку роботс.ткт.
Које странице треба да онемогућите са Гооглебота? Добро је да СЕО сајта онемогући следеће категорије страница.
- Дуплиране странице (попут страница прилагођених штампачу)
- Странице са захвалницама пратећи налоге на бази формулара
- Обрасци за наруџбу или информације
- Контакт странице
- Странице за пријаву
- Странице „продаје“ водећег магнета
Не занемарујте своју датотеку Роботс.ткт
Највећа грешка нових власника веб страница јеникад не гледајући њихову датотеку роботс.ткт. Најгора ситуација могла би бити да датотека роботс.ткт заправо блокира вашу веб локацију или подручја ваше веб локације да се уопште не индексирају.
Обавезно прегледајте датотеку роботс.ткт и проверите да је оптимизована. На овај начин, Гоогле и други важни претраживачи „виде“ све феноменалне ствари које нуде свету са ваше веб локације.
![Придружите се домени активног директорија са системом Виндовс 7 или Виста [Како да]](/images/vista/join-an-active-directory-windows-domain-with-windows-7-or-vista-how-to.png)









Оставите коментар