Co je soubor Robots.txt v doméně?

Jednou z největších chyb pro nové majitele webových stránek není prohlížení jejich souboru robots.txt. Co to vlastně je a proč je to tak důležité? Máme vaše odpovědi.
Pokud vlastníte web a staráte se o nějZdraví SEO, měli byste se velmi dobře seznámit se souborem robots.txt ve vaší doméně. Věřte tomu nebo ne, to je znepokojivě vysoký počet lidí, kteří rychle spouští doménu, instalují rychlý web WordPress a nikdy se neobtěžují dělat nic se svým souborem robots.txt.
To je nebezpečné. Špatně nakonfigurovaný soubor robots.txt může skutečně zničit stav SEO vašeho webu a poškodit všechny šance, které můžete mít pro zvýšení provozu.
Co je soubor Robots.txt?
The Robots.txt soubor je výstižně pojmenován, protože je to v podstatěsoubor, který obsahuje pokyny pro webové roboty (například roboty vyhledávacích strojů) o tom, jak a co mohou procházet na vašem webu. Toto je webový standard, po kterém následují webové stránky od roku 1994 a všichni hlavní weboví prohledávače dodržují tento standard.
Soubor je uložen v textovém formátu (s a.txt rozšíření) v kořenové složce vašeho webu. Ve skutečnosti můžete soubor robot.txt libovolného webu zobrazit pouhým zadáním domény, za kterým následuje /robots.txt. Pokud to zkusíte s groovyPost, uvidíte příklad dobře strukturovaného souboru rob.txt.

Soubor je jednoduchý, ale účinný. Tento příklad souboru nerozlišuje mezi roboty. Příkazy jsou vydávány všem robotům pomocí User-agent: * směrnice. To znamená, že všechny příkazy, které jej následují, se vztahují na všechny roboty, které navštíví web, aby jej procházely.
Zadání webových prohledávačů
Můžete také určit specifická pravidla prokonkrétní webové prohledávače. Můžete například povolit Googlebotu (webový prohledávač Google) procházet všechny články na vašem webu, ale možná budete chtít ruský webový prohledávač Yandex Bot zakázat procházení článků na vašem webu, které obsahují nepřehledné informace o Rusku.
Existují stovky webových prohledávačů, které vyhledávají na internetu informace o webech, ale zde je uvedeno 10 nejčastějších, o které byste se měli zajímat.
- Googlebot: Vyhledávač Google
- Bingbot: Vyhledávací stroj společnosti Microsoft Bing
- Slurp: Vyhledávací modul Yahoo
- DuckDuckBot: Vyhledávací modul DuckDuckGo
- Baiduspider: Čínský vyhledávací nástroj Baidu
- YandexBot: Ruský vyhledávací modul Yandex
- Exabot: Francouzský vyhledávací stroj Exalead
- Facebot: Procházení Facebooku
- ia_archiver: Alexův webový prohledávač
- MJ12bot: Velká databáze indexování odkazů
Pokud chcete, vezměte příklad scénáře výšeChcete-li Googlebotovi umožnit indexovat vše na vašem webu, ale chtěli jste zablokovat Yandexu v indexování vašeho ruského článku, přidejte do souboru robots.txt následující řádky.
User-agent: googlebot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
User-agent: yandexbot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
Disallow: /russia/
Jak vidíte, první sekce pouze blokujeGoogle z procházení vaší přihlašovací stránky WordPress a administrativních stránek. Druhá sekce blokuje Yandex ze stejného, ale také z celé oblasti vašeho webu, kde jste publikovali články s obsahem proti Rusku.
Toto je jednoduchý příklad, jak můžete používat Zakázat příkaz k ovládání konkrétních webových prohledávačů, které navštíví váš web.
Další příkazy souboru Robots.txt
Zakázat není jediný příkaz, ke kterému máte přístup v souboru robots.txt. Můžete také použít kterýkoli z dalších příkazů, které nasměrují, jak robot může procházet váš web.
- Zakázat: Řekne agentovi uživatele, aby se vyhnul procházení konkrétních adres URL nebo celých částí vašeho webu.
- Dovolit: Umožňuje doladit konkrétní stránky nebo podsložky na vašem webu, přestože jste nadřazenou složku mohli zakázat. Například můžete zakázat: / about /, ale pak povolit: / about / ryan /.
- Zpoždění procházení: Tím se prozradí prolézacímu modulu, aby počkal xx počet sekund, než začne procházet obsah webu.
- Mapa stránek: Poskytněte vyhledávačům (Google, Ask, Bing a Yahoo) umístění souborů XML.
Mějte na paměti, že roboti budou pouze poslouchejte příkazy, které jste zadali, když zadáte název robota.
Častou chybou, kterou lidé dělají, je zakázání oblastí jako / wp-admin / od všech robotů, ale pak zadejte sekci googlebot a zakazujte pouze další oblasti (jako / about /).
Protože roboti se řídí pouze příkazy, které určíte v jejich části, je třeba znovu zopakovat všechny ostatní příkazy, které jste zadali pro všechny roboty (pomocí * user-agent).
- Zakázat: Příkaz používaný k tomu, aby uživatelskému agentovi řekl, aby neprolézal konkrétní URL. Pro každou adresu URL je povolen pouze jeden řádek „Zakázat:“.
- Povolit (platí pouze pro Googlebot): Příkaz informující Googlebot, že má přístup na stránku nebo podsložku, i když může být její nadřazená stránka nebo podsložka zakázána.
- Zpoždění procházení: Kolik sekund by měl prolézací modul čekat před načtením a procházením obsahu stránky. Googlebot tento příkaz neuznává, ale rychlost procházení lze nastavit v Google Search Console.
- Mapa stránek: Používá se k vyvolání umístění souborů XML Sitemap spojených s touto adresou URL. Tento příkaz je podporován pouze společnostmi Google, Ask, Bing a Yahoo.
Nezapomeňte, že soubor robots.txt má pomoci legitimním robotům (například robotům vyhledávacích strojů) procházet vaše stránky efektivněji.
Existuje spousta škodlivých prohledávačůkteré procházejí váš web a dělají věci, jako je poškrábání e-mailových adres nebo krádež obsahu. Pokud chcete zkusit použít soubor robots.txt k blokování těchto prolézacích modulů v procházení něčeho na vašem webu, neobtěžujte se. Tvůrci těchto prolézacích modulů obvykle ignorují vše, co jste vložili do souboru robots.txt.
Proč něco zakazovat?
Pro většinu majitelů webových stránek je prvořadým cílem zajistit, aby vyhledávač Google mohl procházet co nejvíce kvalitního obsahu na vašem webu.
Google však vydává pouze omezené výdaje rozpočet procházení a rychlost procházení na jednotlivých stránkách. Míra procházení udává, kolik požadavků Googlebot za sekundu na váš web podá během události procházení.
Důležitější je rozpočet na procházenímnoho celkových požadavků, které Googlebot provede, aby prohledal váš web v jedné relaci. Google „utrácí“ svůj rozpočet pro procházení zaměřením na oblasti vašeho webu, které jsou velmi populární nebo se nedávno změnily.
Na tyto informace nejste slepí. Pokud navštívíte Nástroje pro webmastery Google, uvidíte, jak prolézací modul zpracovává vaše stránky.

Jak vidíte, prolézací modul udržuje aktivitu na vašem webu každý den stále konstantní. Prohledává všechny weby, ale pouze ty, které považuje za nejdůležitější.
Proč se rozhodnout, co je, nechte na robotu Googlebotdůležité, když můžete pomocí souboru robots.txt sdělit, jaké jsou nejdůležitější stránky? Zabráníte tak Googlebotu plýtvat časem na stránkách s nízkou hodnotou na vašem webu.
Optimalizace rozpočtu procházení
Nástroje pro webmastery Google také umožňují zkontrolovat, zda Googlebot čte soubor robots.txt v pořádku a zda se nevyskytují nějaké chyby.
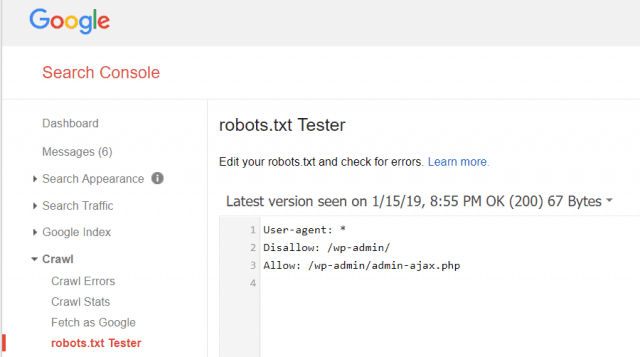
To vám pomůže ověřit, zda jste soubor robots.txt správně strukturovali.
Jaké stránky byste měli zakázat Googlebotu? Je dobré, aby vaše stránky SEO zakázaly následující kategorie stránek.
- Duplicitní stránky (jako stránky vhodné pro tisk)
- Děkuji stránkám, které sledují objednávky na základě formuláře
- Formuláře dotazů k objednávkám nebo informacím
- Kontaktní stránky
- Přihlašovací stránky
- Prodejní stránky olovnatých magnetů
Neignorujte váš soubor Robots.txt
Největší chybou nových majitelů webových stránek je, ženikdy se nedíval na jejich soubor robots.txt. Nejhorší situace může být, že soubor robots.txt ve skutečnosti blokuje váš web nebo jeho části, aby se vůbec neprolezl.
Zkontrolujte soubor robots.txt a ujistěte se, že je optimalizovaný. Tímto způsobem Google a další důležité vyhledávače „uvidí“ všechny báječné věci, které na svém webu nabízíte světu.
![Připojte se k doméně Windows Active Directory se systémem Windows 7 nebo Vista [How-To]](/images/vista/join-an-active-directory-windows-domain-with-windows-7-or-vista-how-to.png)









Zanechat komentář