Τι είναι το αρχείο Robots.txt σε έναν τομέα;

Ένα από τα μεγαλύτερα λάθη για τους νέους ιδιοκτήτες ιστότοπων δεν εξετάζει το αρχείο robots.txt. Τι είναι ούτως ή άλλως και γιατί είναι τόσο σημαντικό; Έχουμε τις απαντήσεις σας.
Εάν είστε κάτοχος ιστότοπου και ενδιαφέρεστε για το δικτυακό σας τόποSEO υγεία, θα πρέπει να είστε πολύ εξοικειωμένοι με το αρχείο robots.txt στον τομέα σας. Πιστέψτε το ή όχι, που είναι ένας ανησυχητικά υψηλός αριθμός ανθρώπων που ξεκινούν γρήγορα έναν τομέα, εγκαταστήστε έναν γρήγορο ιστότοπο WordPress και ποτέ μην κάνετε τον κόπο να κάνετε τίποτα με το αρχείο robots.txt.
Αυτό είναι επικίνδυνο. Ένα κακό διαμορφωμένο αρχείο robots.txt μπορεί πραγματικά να καταστρέψει την υγεία του SEO του ιστότοπού σας και να καταστρέψει τυχόν πιθανότητες που μπορεί να έχετε για την αύξηση της επισκεψιμότητάς σας.
Τι είναι το αρχείο Robots.txt;
ο Robots.txt το αρχείο είναι εύστοχα ονομάζεται επειδή είναι ουσιαστικά ααρχείο που απαριθμεί οδηγίες για τα ρομπότ Ιστού (όπως τα ρομπότ μηχανών αναζήτησης) για το πώς και τι μπορούν να ανιχνεύσουν στον ιστότοπό σας. Αυτό είναι ένα πρότυπο διαδικτύου που ακολουθείται από ιστοσελίδες από το 1994 και όλες οι μεγάλες crawlers ιστού συμμορφώνονται με το πρότυπο.
Το αρχείο αποθηκεύεται σε μορφή κειμένου (με.txt) στον ριζικό φάκελο του ιστότοπού σας. Στην πραγματικότητα, μπορείτε να δείτε το αρχείο robot.txt κάθε ιστοτόπου, μόνο πληκτρολογώντας τον τομέα που ακολουθεί το /robots.txt. Αν το δοκιμάσετε με το groovyPost, θα δείτε ένα παράδειγμα ενός καλά δομημένου αρχείου robot.txt.

Το αρχείο είναι απλό αλλά αποτελεσματικό. Αυτό το αρχείο αρχείου δεν κάνει διάκριση μεταξύ των ρομπότ. Οι εντολές εκδίδονται σε όλα τα ρομπότ χρησιμοποιώντας το Χρήστης-πράκτορας: * διευθυντικός. Αυτό σημαίνει ότι όλες οι εντολές που ακολουθούν ισχύουν για όλα τα ρομπότ που επισκέπτονται τον ιστότοπο για να το ανιχνεύσουν.
Καθορισμός διαδικτυακών ανιχνευτών
Θα μπορούσατε επίσης να ορίσετε συγκεκριμένους κανόνες γιασυγκεκριμένες ανιχνευτές ιστού. Για παράδειγμα, μπορείτε να επιτρέψετε στο Googlebot να ανιχνεύσει όλα τα άρθρα στον ιστότοπό σας, αλλά ίσως θελήσετε να απορρίψετε το ρωσικό crawler ιστότοπου Yandex Bot από την ανίχνευση άρθρων στον ιστότοπό σας που έχουν αποθαρρυντικές πληροφορίες σχετικά με τη Ρωσία.
Υπάρχουν εκατοντάδες ανιχνευτές ιστού που καθαρίζουν το Διαδίκτυο για πληροφορίες σχετικά με τους ιστότοπους, αλλά οι 10 πιο συνηθισμένοι που πρέπει να ανησυχείτε παρατίθενται εδώ.
- Googlebot: Μηχανή αναζήτησης Google
- Bingbot: Η μηχανή αναζήτησης Microsoft της Bing
- Slurp: Μηχανή αναζήτησης Yahoo
- DuckDuckBot: Μηχανή αναζήτησης DuckDuckGo
- Baiduspider: Κινεζική μηχανή αναζήτησης Baidu
- YandexBot: Ρωσική μηχανή αναζήτησης Yandex
- Exabot: Γαλλική μηχανή αναζήτησης Exalead
- Facebot: Το crawling bot του Facebook
- ia_archiver: Crawler κατάταξης ιστού της Alexa
- MJ12bot: Μεγάλη βάση δεδομένων ευρετηρίου σύνδεσης
Λαμβάνοντας το παράδειγμα σεναρίου παραπάνω, εάν το θέλατεγια να επιτρέψετε στο Googlebot να ευρετηριάσει τα πάντα στον ιστότοπό σας, αλλά ήθελε να εμποδίσει το Yandex από την ευρετηρίαση του ρωσικού περιεχομένου του άρθρου σας, θα προσθέσετε τις παρακάτω γραμμές στο αρχείο robots.txt.
User-agent: googlebot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
User-agent: yandexbot
Disallow: Disallow: /wp-admin/
Disallow: /wp-login.php
Disallow: /russia/
Όπως μπορείτε να δείτε, το πρώτο τμήμα μπλοκάρει μόνοGoogle από την ανίχνευση της σελίδας σύνδεσής σας WordPress και των σελίδων διαχείρισης. Η δεύτερη ενότητα αποκλείει το Yandex από το ίδιο, αλλά και από ολόκληρη την περιοχή του ιστότοπού σας, όπου έχετε δημοσιεύσει άρθρα με περιεχόμενο κατά της Ρωσίας.
Αυτό είναι ένα απλό παράδειγμα του τρόπου με τον οποίο μπορείτε να χρησιμοποιήσετε το Απαγορεύω εντολή για τον έλεγχο συγκεκριμένων ανιχνευτών ιστού που επισκέπτονται τον ιστότοπό σας.
Άλλες εντολές Robots.txt
Το Disallow δεν είναι η μόνη εντολή στην οποία έχετε πρόσβαση στο αρχείο robots.txt. Μπορείτε επίσης να χρησιμοποιήσετε οποιαδήποτε από τις άλλες εντολές που θα κατευθύνουν τον τρόπο με τον οποίο ένα ρομπότ μπορεί να ανιχνεύσει τον ιστότοπό σας.
- Απαγορεύω: Ενημερώνει τον χρήστη-παράγοντα για να αποφύγει την ανίχνευση συγκεκριμένων διευθύνσεων URL ή ολόκληρων ενοτήτων του ιστότοπού σας.
- Επιτρέπω: Σας επιτρέπει να τελειοποιήσετε συγκεκριμένες σελίδες ή υποφακέλους στον ιστότοπό σας, παρόλο που ενδέχεται να έχετε απορρίψει έναν γονικό φάκελο. Για παράδειγμα, μπορείτε να απαγορεύσετε: / about /, αλλά στη συνέχεια επιτρέψτε: / about / ryan /.
- Απόσπαση ανίχνευσης: Αυτό ενημερώνει τον ανιχνευτή να περιμένει xx αριθμό δευτερολέπτων πριν αρχίσει να ανιχνεύει το περιεχόμενο του ιστότοπου.
- Χάρτης ιστοτόπου: Παρέχετε στις μηχανές αναζήτησης (Google, Ask, Bing και Yahoo) την τοποθεσία των χάρτες ιστοτόπου XML.
Λάβετε υπόψη ότι τα bots θα μόνο ακούστε τις εντολές που δώσατε όταν καθορίζετε το όνομα του bot.
Ένα κοινό λάθος που κάνουν οι χρήστες είναι να απαγορεύσουν περιοχές όπως το / wp-admin / από όλα τα bots, αλλά στη συνέχεια να καθορίσετε μια ενότητα googlebot και να αποκλείσετε μόνο άλλους τομείς (όπως / about /).
Δεδομένου ότι οι μποτ μόνο ακολουθούν τις εντολές που καθορίζετε στην ενότητα τους, θα πρέπει να επαναλάβετε όλες τις άλλες εντολές που έχετε καθορίσει για όλα τα bots (χρησιμοποιώντας το * user-agent).
- Απαγορεύω: Η εντολή που χρησιμοποιήθηκε για να πει ένα χρήστη-παράγοντα να μην ανιχνεύσει συγκεκριμένη διεύθυνση URL. Για κάθε διεύθυνση URL επιτρέπεται μόνο μία γραμμή "Disallow:".
- Επιτρέψτε (ισχύει μόνο για το Googlebot): Η εντολή να λέει στο Googlebot ότι μπορεί να αποκτήσει πρόσβαση σε μια σελίδα ή υποφάκελο, παρόλο που η γονική της σελίδα ή ο υποφάκελος ενδέχεται να μην επιτρέπεται.
- Απόσπαση ανίχνευσης: Πόσα δευτερόλεπτα πρέπει να περιμένει ένας ανιχνευτής πριν φορτώσει και ανιχνεύσει περιεχόμενο σελίδας. Έχετε υπόψη ότι το Googlebot δεν αναγνωρίζει αυτή την εντολή, αλλά η ρυθμός ανίχνευσης μπορεί να οριστεί στην Κονσόλα αναζήτησης Google.
- Sitemap: Χρησιμοποιείται για την κλήση της θέσης ενός χάρτη ιστότοπων XML που σχετίζεται με αυτήν τη διεύθυνση URL. Σημειώστε ότι αυτή η εντολή υποστηρίζεται μόνο από την Google, Ask, Bing και Yahoo.
Έχετε υπόψη ότι το robots.txt έχει σκοπό να βοηθήσει νόμιμους bots (όπως οι μηχανές αναζήτησης) να ανιχνεύσουν τον ιστότοπό σας πιο αποτελεσματικά.
Υπάρχουν πολλά κακόβουλα crawlers εκεί έξωπου ανιχνεύουν τον ιστότοπό σας για να κάνουν πράγματα όπως να εξαλείψουν τις διευθύνσεις ηλεκτρονικού ταχυδρομείου ή να κλέψουν το περιεχόμενό σας. Εάν θέλετε να δοκιμάσετε να χρησιμοποιήσετε το αρχείο robots.txt για να αποκλείσετε την ανίχνευση οτιδήποτε στον ιστότοπό σας, μην ανησυχείτε. Οι δημιουργοί αυτών των προγραμμάτων ανίχνευσης αγνοούν συνήθως τίποτα που έχετε θέσει στο αρχείο robots.txt.
Γιατί να αποκλείσετε κάτι;
Η λήψη της μηχανής αναζήτησης της Google για την ανίχνευση όσο το δυνατόν καλύτερης ποιότητας περιεχομένου στον ιστότοπό σας είναι πρωταρχική ανησυχία για τους περισσότερους κατόχους ιστότοπων.
Ωστόσο, η Google καταναλώνει περιορισμένο μόνο crawl budget και ποσοστό ανίχνευσης σε επιμέρους τοποθεσίες. Ο ρυθμός ανίχνευσης είναι ο αριθμός των αιτήσεων ανά δευτερόλεπτο που θα κάνει ο Googlebot στον ιστότοπό σας κατά τη διάρκεια του συμβάντος ανίχνευσης.
Πιο σημαντικό είναι ο προϋπολογισμός ανίχνευσης, ο οποίος είναι ο τρόποςπολλά συνολικά αιτήματα που θα κάνει η Googlebot για να ανιχνεύσει τον ιστότοπό σας σε μία συνεδρία. Το Google "ξοδεύει" τον προϋπολογισμό ανίχνευσης εστιάζοντας σε περιοχές του ιστότοπού σας που είναι πολύ δημοφιλείς ή έχουν αλλάξει πρόσφατα.
Δεν είστε τυφλοί σε αυτές τις πληροφορίες. Εάν επισκέπτεστε τα Εργαλεία για Webmasters Google, μπορείτε να δείτε πώς ο ανιχνευτής χειρίζεται τον ιστότοπό σας.

Όπως μπορείτε να δείτε, ο ανιχνευτής διατηρεί την δραστηριότητά του στον ιστότοπό σας αρκετά σταθερή κάθε μέρα. Δεν ανιχνεύει όλους τους ιστότοπους, αλλά μόνο εκείνους που θεωρεί ότι είναι οι πιο σημαντικοί.
Γιατί αφήστε το στο Googlebot να αποφασίσει τι είναισημαντικό για τον ιστότοπό σας, όταν μπορείτε να χρησιμοποιήσετε το αρχείο robots.txt για να το πείτε ποιες είναι οι πιο σημαντικές σελίδες; Αυτό θα εμποδίσει το Googlebot να χάσει χρόνο σε σελίδες χαμηλής αξίας στον ιστότοπό σας.
Βελτιστοποίηση του Προϋπολογισμού Crawl σας
Επίσης, τα Εργαλεία για Webmasters της Google σάς επιτρέπουν να ελέγξετε αν το Googlebot διαβάζει το αρχείο robots.txt σας και τι υπάρχει κάποιο σφάλμα.
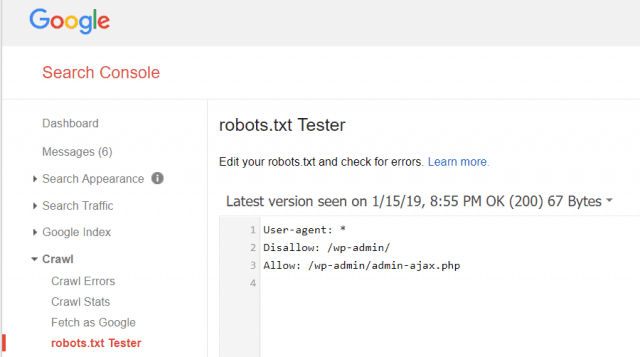
Αυτό σας βοηθά να επαληθεύσετε ότι έχετε διαρθρώσει σωστά το αρχείο robots.txt.
Ποιες σελίδες θα πρέπει να αποκλείσετε από το Googlebot; Είναι καλό για την ιστοσελίδα σας SEO να αποκλείσει τις ακόλουθες κατηγορίες σελίδων.
- Διπλές σελίδες (όπως σελίδες φιλικές προς τον εκτυπωτή)
- Σας ευχαριστούμε για τις σελίδες που ακολουθούν παραγγελίες βάσει φόρμα
- Εντολές παραγγελίας ή πληροφοριών
- Σελίδες επαφών
- Σελίδες σύνδεσης
- Προωθήστε τις σελίδες "πωλήσεων" μαγνητών
Μην αγνοήσετε το αρχείο Robots.txt
Το μεγαλύτερο λάθος που κάνουν οι νέοι ιδιοκτήτες ιστοτόπων είναιποτέ ούτε καν κοιτάζοντας το αρχείο robots.txt. Η χειρότερη κατάσταση θα μπορούσε να είναι ότι το αρχείο robots.txt εμποδίζει στην πραγματικότητα τον ιστότοπό σας ή τις περιοχές του ιστότοπού σας να μην ανιχνεύσουν καθόλου.
Βεβαιωθείτε ότι έχετε ελέγξει το αρχείο robots.txt και βεβαιωθείτε ότι έχει βελτιστοποιηθεί. Με αυτόν τον τρόπο, η Google και άλλες σημαντικές μηχανές αναζήτησης "βλέπουν" όλα τα υπέροχα πράγματα που προσφέρετε στον κόσμο με τον ιστότοπό σας.
![Συμμετοχή σε ένα Windows Domain Windows Active Directory με Windows 7 ή Vista [Πώς να]](/images/vista/join-an-active-directory-windows-domain-with-windows-7-or-vista-how-to.png)









Αφήστε ένα σχόλιο